












What Tellius is All About
Go beyond static dashboards to get instant answers, deep insights, and agentic flows that drive outsized outcomes.


Faster Insights, Unstoppable Impact
ChatGPT-like Interface to all your enterprise data
Interact with enterprise data conversationally, facilitating better and faster decision-making.

Shortcut to WHY with AI Insights & Narratives
Analyze billions of datapoints to get to the hidden root causes and key drivers, saving lots of time

Put GenAI to Work
Use & build AI agents and agentic flows that transform data into immediate actions, effectively creating an AI analyst for everyone


Answer + Act on Any Enterprise Question
& reporting
code-based predictive analytics
Conversations, Insights + Agentic Flows
Empower your people. Accelerate work.
Every Quarter.
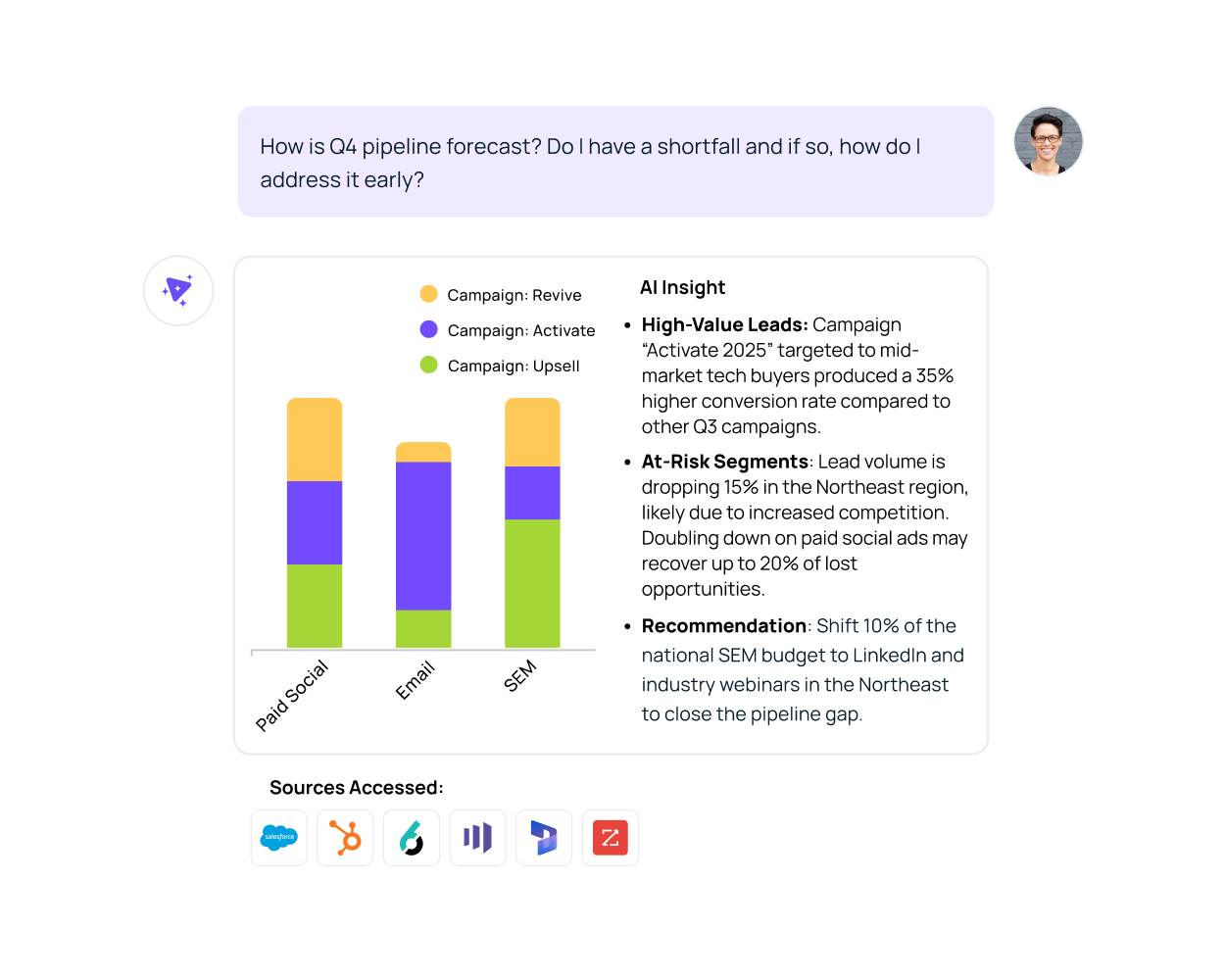
Supercharge deal velocity and accelerate revenue with AI-powered RevOps Intelligence. Spot hidden risks, enable every seller, and trigger next-best actions through by unifying your CRM, field activity, and revenue tools through an intuitive conversational interface.


Unify all your data, automate variance analysis, deliver unstoppable forecasts, and uncover the ‘why’ —without the spreadsheet chaos.


Your missing intelligence layer—unifying data, metrics, & knowledge—into a conversational insights engine that empowers true self-service analytics bridging the gap between questions and actionable insights.


Integrate all your supply chain data, automate demand forecasting, uncover bottlenecks, and enhance efficiency—without the guesswork or delays.


Consolidate all your marketing data, automate campaign optimization, uncover customer insights, and drive impactful strategies—without the manual effort or uncertainty.

Unleash the full power of data
to insights











Breakthrough Ideas, Right at Your Fingertips
Dig into our latest guides, webinars, whitepapers, and best practices that help you leverage data for tangible, scalable results.

What’s Killing Your E-Commerce Revenue Deep Dives (and How Custom Workflows Fix It)
E-commerce teams shouldn’t need a 60-slide deck every time revenue drops or CAC rises. This post shows how to turn your best “revenue deep dive” into a reusable, agent-executed workflow in Tellius. Learn how Kaiya Agent Mode uses your semantic layer to analyze product mix, segments, and funnels, explain what actually drove revenue changes, and model what-if scenarios like 10% price increases in top categories in just a few minutes.
.png)
AI Analytics & Agentic AI: Definition, Benefits, and Real-World Examples
This 2025 guide to AI analytics covers definition, architecture, and examples—plus how agentic AI with a semantic layer and orchestrated AI agents turns insights into approved action, reducing time-to-action and delivering measurable impact.
.png)
Agents vs. Workflows. Why not both?
AI agents and workflow automation are often treated as competing approaches, but the real power emerges when they work together. As agents evolve from simple chatbots to autonomous decision-makers and automation platforms become more intelligent and flexible, organizations can combine both to achieve higher reliability, faster execution, and deeper insights. This post breaks down the agent and automation spectrums, explains why Mode 1 (Execute) and Mode 2 (Explore) are both essential, and shows how their convergence enables smarter, safer, and more scalable AI-driven operations.
.png)

Tellius 5.3: Beyond Q&A—Your Most Complex Business Questions Made Easy with AI
Skip the theoretical AI discussions. Get a practical look at what becomes possible when you move beyond basic natural language queries to true data conversations.

PMSA Fall Symposium 2025 in Boston
Join Tellius at PMSA Oct 2–3 for two can’t-miss sessions: Regeneron on how they’re scaling GenAI across the pharma brand lifecycle, and a hands-on workshop on AI Agents for sales, HCP targeting, and access wins. Discover how AI-powered analytics drives commercial success.
.png)
Tellius AI Agents: Driving Real Analysis, Action, + Enterprise Intelligence
Tellius AI Agents transform business intelligence with dedicated AI squads that automate complex analysis workflows without coding. Join our April 17th webinar to discover how these agents can 100x enterprise productivity by turning questions into actionable insights, adapting to your unique business processes, and driving decisions with trustworthy, explainable intelligence.