AI Agents for CPG: The 2026 Field Guide to Use Cases, Vendors, and What's Actually Real


AI agents for CPG are software systems that run multi-step commercial work on their own: sensing demand, watching POS and shelf conditions, diagnosing why share or a promotion moved, prepping the retailer argument, and then recommending or triggering the next action. The difference from the tools you already own is that an agent doesn't wait for a question. It works the problem.
That's the promise, anyway. A lot of what gets sold under the "agentic AI for CPG" banner in 2026 is a forecasting model or a chatbot with a new coat of paint. This guide sorts the real from the repackaged: which use cases work today, which vendors are actually doing the thing, and where the whole effort tends to fall apart.
The short version:
- Most of it is repackaged. Gartner estimates only about 130 vendors industry-wide are truly agentic, and expects more than 40% of agentic AI projects to be cancelled by the end of 2027. The burden of proof is on the vendor.
- A few use cases are real now. Syndicated and POS analysis, demand sensing, retail execution, and trade/revenue growth management are where agents earn their keep. They work in direct proportion to how clean and connected your data is.
- It's a stack, not a shopping list. Data-layer enablers, analysis agents, innovation agents, and execution suites each do a different job. The deployments worth copying stitch several together rather than betting on one.
What an "AI agent" actually means here (and what it doesn't)
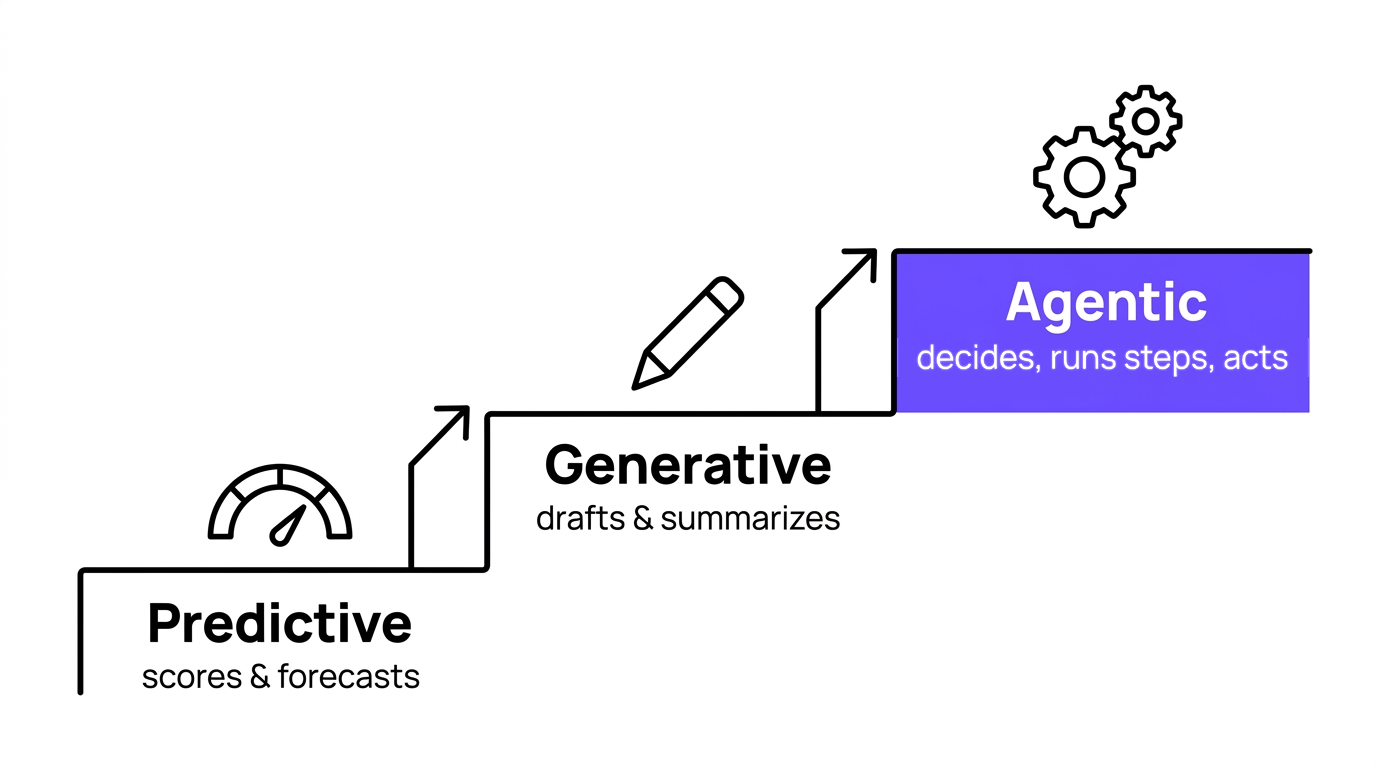
Three different capabilities get sold as "agentic," and only one of them earns the word.
- Predictive AI scores and forecasts (ex. “demand will dip 8% in the Southeast next month”)
- Generative AI drafts and summarizes (ex. writes the PDP copy or the first pass of a claim)
- Agentic AI is supposed to do something more, ie., take a goal, decide which questions to ask, run the steps across more than one system, check its own work along the way, and then either hand back a finished output or take an action.
Consider a promotion. The old setup gives you a post-event report two weeks after the promo closes, showing it underperformed by 12%. An agent catches the same gap on day three, checks it against the retailer's contract terms, adjusts the mechanics inside the limits you've approved, and flags the underperforming stores to the account manager while there's still time to act. Unlike the report, which tells you what already happened, the agent moves while the window is open. A dashboard describes; an operator acts. Most products land somewhere in between and market themselves as operators.
This is where the skepticism has to live, because "agent" has become a marketing word. Gartner's read is blunt: of the thousands of vendors claiming agentic AI, it estimates roughly 130 are the real thing, and it predicts over 40% of agentic AI projects will be cancelled by the end of 2027 on cost, unclear value, or weak controls. A dashboard with an LLM summary bolted on doesn't clear that bar, no matter how it's packaged. Neither does a single-prompt copilot, or a fixed RPA script. That doesn't make any of them useless. It makes them something other than what's on the label.
Ask any demo the same question twice. A real CPG agent gives you the same answer both times, because trade and category numbers get audited and compared period over period. If the answer drifts between runs, you don't have something you can take into a line review.
The market is a stack, not a list

When people ask "who are the AI agent vendors for CPG," they want a list. The more useful model is a stack, because these vendors aren't competing for one slot. They're doing different jobs at different layers, and the deployments that work usually combine a few of them.
Roughly, there are five camps:
- Data-layer enablers make your CPG data legible to an agent in the first place (Corvera, Crisp, and services firms like Sigmoid and LatentView). This is the unglamorous layer that decides whether anything above it works.
- Reasoning and decision agents decompose the why and reconcile across sources: why did share drop, how much was price versus lost distribution versus a competitor's promo, and does the answer hold when a CFO checks it. They read structured, unstructured, and syndicated data as one and return a finished, auditable answer. This is the layer Tellius occupies.
- Insight and innovation agents scan consumers, trends, and claims for product teams (Market Logic, Writer, Tastewise).
- Execution and commercial-ops suites are the RGM, trade, demand-planning, and retail-execution incumbents adding agents to platforms you may already run (o9, Blue Yonder, RELEX, SymphonyAI, Anaplan, Aforza, Pricefx, Vividly, Trax).
- Syndicated-data owners (NielsenIQ, Circana) are bolting AI onto the panels everyone licenses. They're the least agentic of the group and the most strategically placed, because they own data the agents need.
A perfect-store agent that spots an out-of-stock is worthless if it can't see the syndicated data explaining why the category is soft, and a sharp RGM recommendation is worthless if it never reaches the account manager before the JBP meeting. Value compounds across layers. So "just buy an agent" is the wrong question. The right one is which layer is your weakest link.
For where Tellius fits: Tellius is Decision AI for the enterprise — the intelligence layer connecting your data to your decisions, purpose-built for commercial teams. In stack terms, that's the analysis-and-reasoning layer: reading structured, unstructured, and syndicated data as one, diagnosing why a number moved, and shipping the finished writeup. It doesn't replace your TPM, your demand planner, or your syndicated subscription. It's the layer that answers the questions those tools can't.
The use cases that actually work (and how far along each one is)
CPG agent work clusters into a handful of jobs, and they're at very different stages of maturity. Here's the map:
The read-and-explain jobs are furthest along, because explaining a number is lower-risk than changing one. Syndicated analysis and demand sensing work today because their output is an answer a human acts on. The act-on-it jobs lag, and they lag for good reasons. A wrong claim is a regulatory problem. A bad promotion executed at speed is a margin problem. Governance, not model quality, is what gates the top of that list.
What this looks like in practice
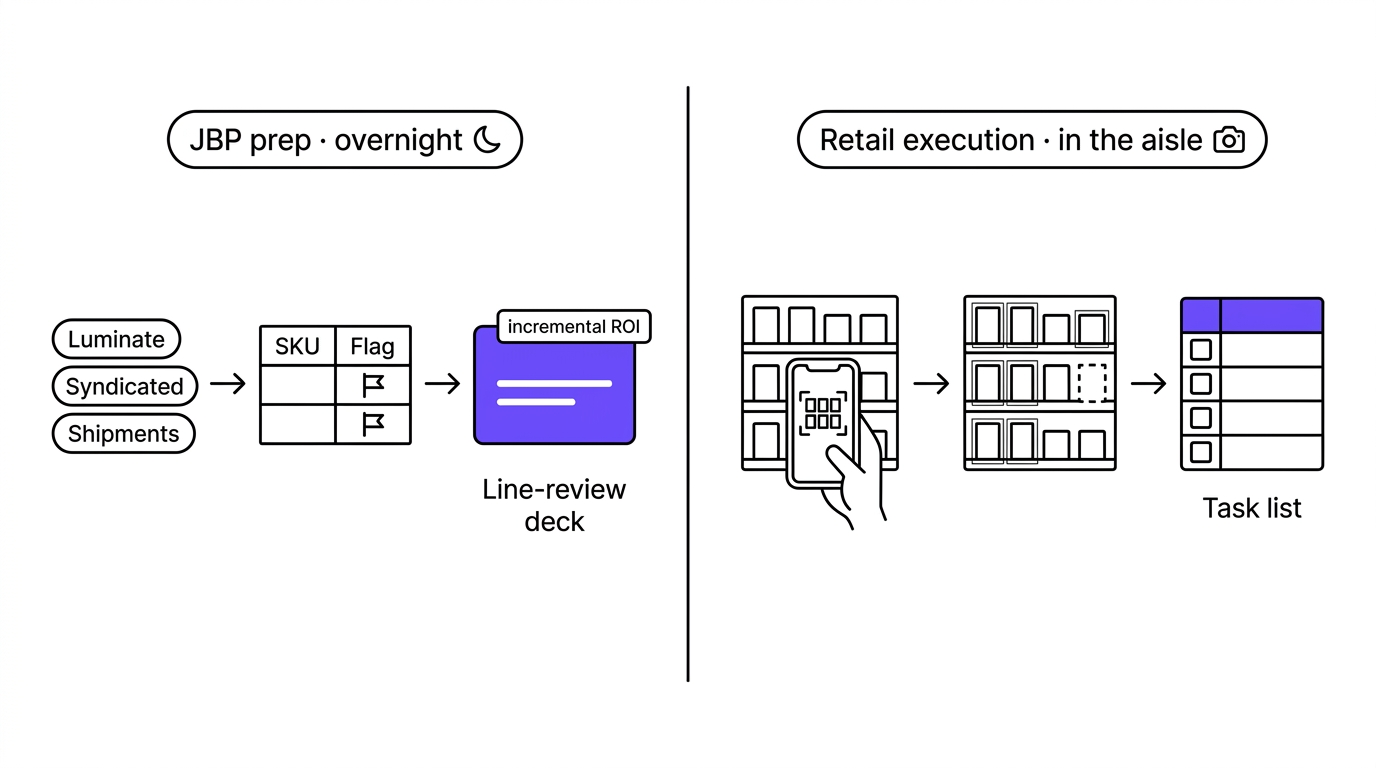
Take a key account manager prepping for a Walmart line review. A JBP-prep agent works the problem overnight: it pulls the account's Luminate data alongside syndicated and internal shipment numbers, decomposes which SKUs are underperforming and in which store clusters, drafts the assortment and pricing argument grounded in the retailer's own data, and assembles the deck. The manager opens a draft with the incremental-ROI math already estimated, instead of a blank template and a week of pulling numbers. The agentic part isn't generating the deck. It's that the system decided which cuts of data mattered for this account and chained the steps without being told each one.
Now take the field. A rep photographs a shelf. A retail-execution agent identifies every SKU in the image, scores it against the planogram, flags the out-of-stocks and wrong facings, and returns a prioritized task list before the rep leaves the aisle. A second photo confirms the fix. The vendors themselves are clear about the limit here: computer vision is good at detection, but on its own it only reports what it sees. The agentic layer is the recommendation and the prediction on top, flagging the store likely to go out of stock before the facing empties, not just the one that already did.
In both, the agent isn't producing content on request; it's deciding what to look at and doing the legwork a person would otherwise spend hours on. The human still runs the account and signs off on the call. The agent handles the pulling, decomposing, and drafting that doesn't scale. That's the right mental model: a power tool for the commercial team, not a replacement for it.
What's real, what's hype, and what kills programs
The failure point in CPG agent programs is almost never the model. It's the data underneath it. Connecting the sources is the part everyone plans for, and it's table stakes. The harder problem is meaning. Your TPM, your syndicated panel, and your shipment system can all use the word "sales" and mean three different things: shipped cases, consumed units, dollars net of trade. Feed those to an agent without resolving the difference and you don't get a gap in the answer, you get a confident wrong one, produced at machine speed.
What closes that gap is a semantic model: a layer that defines what each metric means, how it's calculated, and how the entities relate, so the agent reasons against one definition every time instead of guessing per query. Microsoft and Asper.AI make this point about revenue growth management: the agent needs a domain model mapping KPI meaning, data sources, and entity relationships, or it can't tell one team's version of a number from another's.
And meaning still isn't insight. Something has to sit on top and do the reasoning: decompose the why, apply the right method (price/volume/mix, lift, fair share), and return an answer that reconciles when someone checks it. Connected data feeds the agent. A semantic model tells it what the data means. The reasoning layer turns that into a decision. Skip the semantic model or the reasoning layer and you've automated the production of confident nonsense.
So what's actually in production versus on a slide? The read-and-explain agents are real and running today: syndicated and POS analysis, demand-forecasting ML, retail-execution image recognition, narrow back-office automation. The next tier is real but early, still proving itself inside guardrails: autonomous RGM and trade adjustments, JBP prep, claims and innovation agents, predictive out-of-stock. And then there's the tier that's mostly still a pitch: fully autonomous "lights-out" pricing and trade decisions, agents that "negotiate with retailers," and most of the headline ROI numbers.
On adoption, the picture is mixed. NVIDIA's 2026 State of AI in Retail and CPG survey found 47% of companies using or assessing agentic AI and roughly nine in ten increasing their AI budgets, half of them by 10% or more, though the most-cited barrier to scaling is data, not the technology itself. BCG estimates only about 10% of consumer goods and retail companies have integrated AI agents across their teams and workflows; the much-quoted 800-basis-point upside is a potential, not a banked result. Bain finds only 5% of CPGs have future-proofed their revenue growth management. And McKinsey, which found 71% of CPG companies using AI in at least one function, is clear that no CPG player has truly scaled it, with most stuck in what it calls pilot purgatory.
One more thing about the numbers in this space. Almost all of the vendor figures are self-reported and unaudited. "Profits up 40%," "927% ROI," "research cycles cut 90%": read those as directional vendor claims, not benchmarks. The figures worth leaning on are the survey and analyst ones, because nobody selling you the agent produced them.
Agents are only as good as the data they can read and reason over, and the governance around what they're allowed to do. Forrester expects a third of companies to damage customer experience in 2026 by putting AI in front of customers before it's ready. The teams that get value tend to start with a boring, P&L-specific use case, prove it, and scale from there, rather than buying the autonomy first and hunting for a problem to point it at.
Anatomy of a CPG agent: the five layers
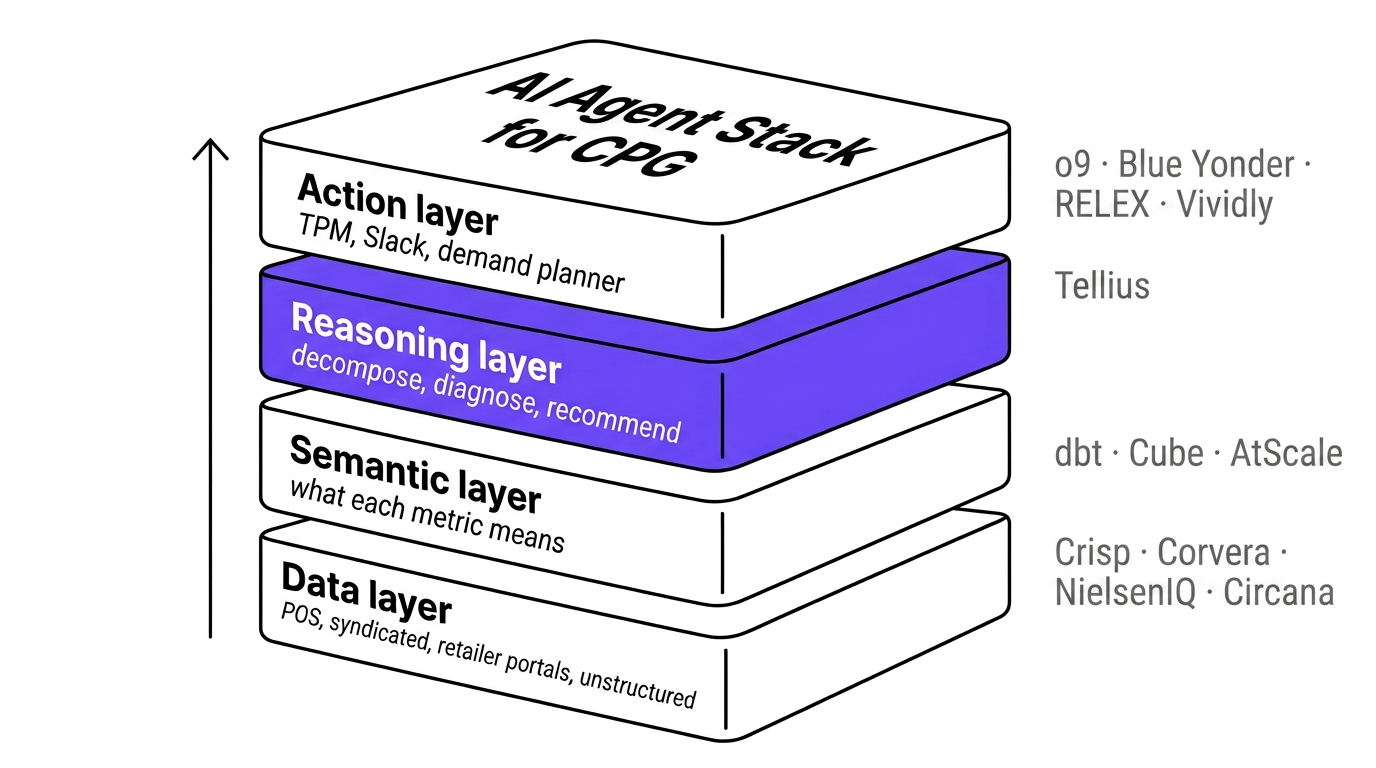
An agent worth deploying has five parts, and the order matters, because each layer depends on the one beneath it.
At the bottom is the data layer: the sources the agent can see. ERP, POS, retailer portals like Walmart Luminate and Kroger's 84.51°, syndicated panels, trade systems, CRM, the product catalog, pricing, promo history, plus the unstructured material most stacks ignore: retailer scorecards, account call notes, reviews. If a source isn't wired in, the agent is blind to it, and most "why did this happen" answers live in the source nobody connected.
Above that is the semantic layer: the model that says what each metric means and how the entities relate, so the agent works against one definition of "sales" or "share" instead of guessing per query. Most of the reasoning quality is won or lost here.
Then the reasoning layer, where the analysis happens. Decomposing a variance, ranking what drove it, applying the right method, checking the result against what the business already knows. This is the difference between an agent that summarizes a dashboard and one that tells you why the number moved.
The action layer is where the answer goes to work: a recommendation written back into the TPM, a task routed to a field rep, a brief dropped into Slack or email, an alert into the demand planner. An insight that never reaches the person who can act on it is a report, not an agent.
Wrapping all four is the governance layer, and in CPG it carries more weight than the diagram suggests. It covers who approves what, what the agent can do without a human, and the audit trail behind every answer. It also covers the permissions most teams forget until legal asks: retailer data-sharing agreements, syndicated licensing rights, which account's data can be used for which purpose. A promo change above a margin threshold, or a move that touches a key account's terms, should route to a person every time.
Of the five, the reasoning layer is where the agent is won or lost, and it's the layer Tellius occupies. Tellius is Decision AI for the enterprise — the intelligence layer connecting your data to your decisions, purpose-built for commercial teams. It sits above the semantic layer and below the action layer: reading structured, unstructured, and syndicated data as one, doing the reasoning, and shipping the finished work where the team already operates. It runs on whichever frontier model you choose rather than replacing it, and every answer traces back to the sources and methods behind it, so it reconciles when a CFO or a compliance team checks. Your warehouses, your BI tools, and your syndicated subscriptions stay where they are. The layer is what turns them into answers.
Inside one question: from "why" to a finished deck
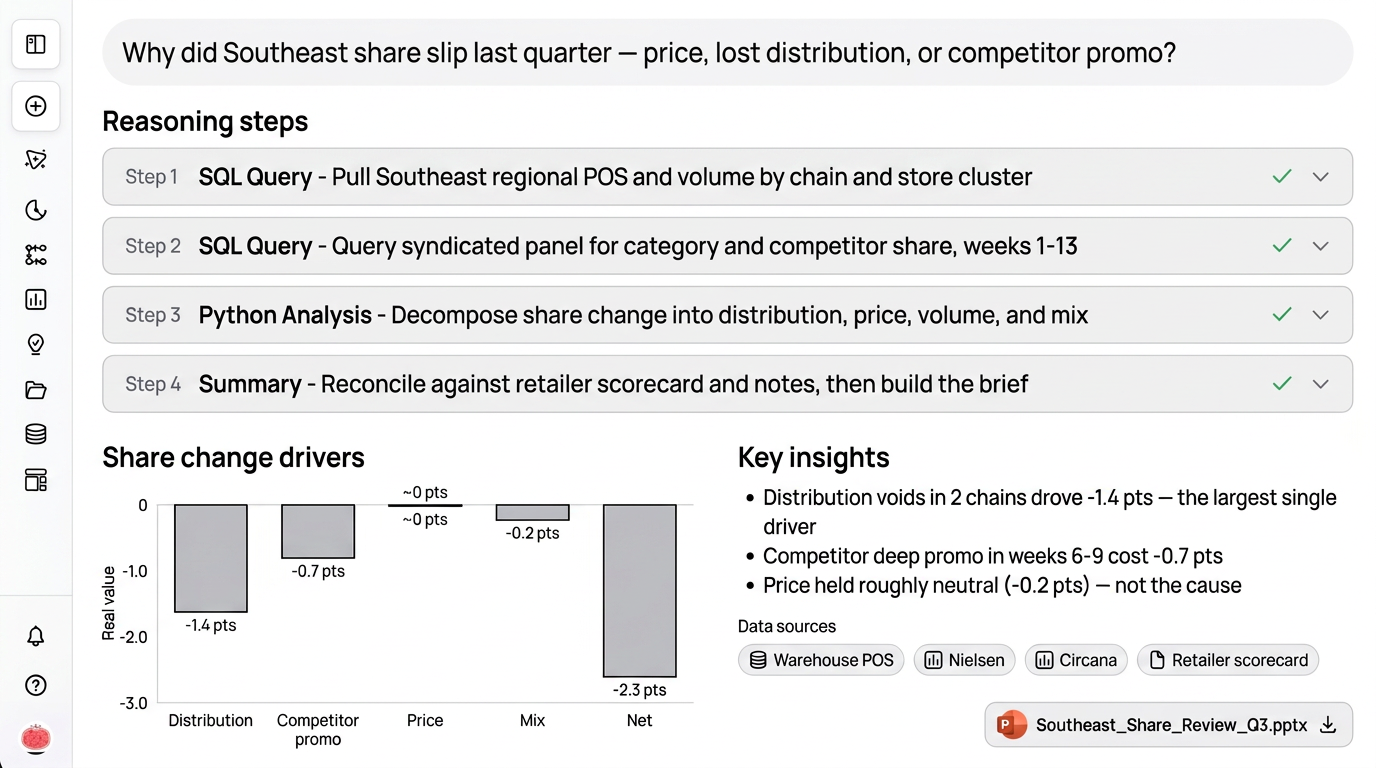
Take a question a category lead actually asks: "Why did our share in the Southeast slip last quarter, and how much of it was price, lost distribution, or a competitor's promo?" It's a why question, it's multi-part, and answering it by hand means a day or two of pulling and reconciling before the analysis even starts.
Here's what the reasoning layer does with it. It breaks the question into steps and runs them: SQL against the warehouse to pull regional POS, queries against the syndicated panel for category and competitor share, Python to decompose the share change into price, volume, distribution, and mix, and a pass over the retailer scorecard and account notes for the part the numbers don't explain. Each source it touches is logged, and every figure in the answer carries a citation back to where it came from, so the output reconciles when someone checks it.
What lands is not a pile of query results. It's a built visualization of the share drivers, a short list of what actually moved the number (distribution voids in two chains, a competitor's deep promo in weeks 6 through 9), and a finished PowerPoint in the team's template, ready to take into the line review. The analyst set the question and owns the call. The system did the legwork that used to eat the week.
How to tell a real agent from a demo
Vendors have gotten good at demos. A few questions cut through faster than a feature list.
- Does it give the same answer twice? Drift between runs means you can't take the output into a line review.
- Does it get smarter, or reset every run? A real agent remembers resolved metric definitions, prior investigations, and your retailer playbooks. One that starts from zero each session is a chatbot with good marketing.
- Can it reconcile your sources? Ask it something that needs POS, syndicated, and shipment data at once. If it can only work one source at a time, it can't do the job that matters.
- Can it show its work? Every number should trace to where it came from and how it was derived. "Trust me" doesn't survive an audit.
- Does it act inside guardrails? You want a system that knows what it can do on its own and what it has to hand to a person. Unbounded autonomy isn't a feature in a business where a wrong move costs margin.
If a vendor stumbles on these, you're looking at predictive ML or a copilot wearing the word "agent." Useful, maybe. Just not what you're being sold.
Where to start
Most CPG agent programs that stall didn't pick the wrong vendor. They started in the wrong place, pointing an agent at an open-ended problem before the data under it could answer one. The sequence that works runs bottom-up.
- Get the foundation right. Connected data, a semantic model, and an audit trail come before any agent. Skip this and everything above it inherits the mess.
- Start with assist. Let agents pull, summarize, and draft while people make every call. Low risk, fast to trust, and it surfaces your data gaps cheaply.
- Move to recommendations inside guardrails. The agent proposes the promo adjustment or the assortment change with its reasoning attached, and a person approves. This is where most CPG teams should aim to live in 2026.
- Let it investigate. Once the foundation holds, give it the open-ended questions. Why did share slip in this region, what's dragging the category. Let it decompose them on its own.
- Scale what works under monitoring. Turn the proven workflows into recurring runs, watch them, and widen from there.
Start with a narrow, P&L-specific problem you can measure, prove it, and expand. The autonomy is the reward for getting the foundation right, not the thing you buy first.
The bottom line
The CPG companies getting real value from agents share one thing, and it isn't the vendor they picked. They got the layer underneath right first: connected data, a semantic model that pins down what every metric means, and a reasoning layer that works across POS, syndicated, and unstructured sources at once. The agent is the visible part. The foundation is what makes it produce an answer you'd put in front of a retailer.
The practical move for 2026 is narrow. Pick one P&L problem where the data mostly already exists and there's more analysis to run than anyone has hours for, a recurring share question or post-promotion read that never gets the time it deserves, put an agent on it in assist or recommend mode, keep a person on approvals, and check whether it saved time or money. If it did, widen. If it didn't, you found where your data or governance breaks for the cost of one use case instead of a platform rollout.
There's also a shift coming from outside the building. Consumers are starting to delegate purchases to their own AI agents, and those agents compare brands on structured product data rather than loyalty. Accenture finds a large share of shoppers already willing to let an agent buy on their behalf. The work of making your data legible to an agent pays off in both directions: for the team reasoning over it inside the building, and for the shopping agent deciding whether to surface your product at all.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!


AI agents for CPG are software systems that run multi-step commercial work on their own: sensing demand, monitoring POS and shelf conditions, diagnosing why share or a promotion moved, and recommending or triggering the next action. Unlike a dashboard or a copilot, an agent decides what to investigate and does the work without being prompted each step.
A dashboard shows you what happened. A copilot answers a question when you ask it. An agent takes a goal, decides which questions to ask, works across multiple systems, checks its own results, and either delivers a finished output or takes an action. The difference is autonomy and chaining, not a better interface.
Both. Read-and-explain agents are running in production today: syndicated and POS analysis, demand-forecasting ML, retail-execution image recognition. Agents that act on decisions, like autonomous trade adjustments or claims generation, are mostly early and guardrail-bound. Fully autonomous pricing or trade decisions remain largely a pitch.
Ask it the same question twice and see if the answer holds. Ask whether it remembers prior work or resets each session. Ask it something that needs POS, syndicated, and shipment data at once. A system that drifts, forgets, or can only read one source at a time is predictive ML or a copilot wearing the word "agent."
Your demand forecasting is predictive AI: it scores what's likely to happen. An agent uses that forecast as one input, then decides what to do about it, flagging the planner, cross-checking inventory, and proposing a revised plan. Prediction tells you the number. The agent acts on it.
The analysis-and-explanation use cases lead, because explaining a number is lower-risk than changing one. Syndicated and POS analysis, demand sensing, and retail-execution detection work now. Trade and RGM adjustment, JBP prep, and claims generation are real but early. Governance, not model quality, gates the use cases that take action.
Three things below the agent: connected data across POS, syndicated, shipment, pricing, and trade systems; a semantic model that defines what each metric means so the agent doesn't confuse shipped cases with consumed units; and an audit trail. Without these, an agent produces fast answers that don't reconcile.
The usual cause isn't the model, it's the data and its meaning. When sources disagree on what "sales" or "share" means and nothing resolves the difference, the agent produces confident wrong answers at speed. Programs also stall when teams buy autonomy first and look for a use case after, instead of starting with one measurable problem.
Three capabilities cut through the demos: can it reason across your sources at once, can it show its work so a number traces back to its origin, and does it stay inside the guardrails you set. A vendor that handles those is worth evaluating further. One that stumbles is selling a copilot.
No. The working model is augmentation: the agent handles the data pulling, decomposition, and drafting that doesn't scale, while the analyst sets the question, reviews the reasoning, and owns the decision. The teams getting value treat agents as a way to give analysts more reach, not as a headcount substitute.
As consumers use AI shopping agents to compare and buy, those agents read structured product data, not packaging or marketing. If your attributes aren't tagged and machine-readable, the agent can't surface or recommend you, regardless of brand strength. Optimizing for the AI shelf means structuring product data so a shopping agent can find and compare it.
Tellius is Decision AI for the enterprise — the intelligence layer connecting your data to your decisions, purpose-built for commercial teams. It occupies the reasoning layer: reading structured, unstructured, and syndicated data as one, diagnosing why a number moved, and shipping the finished work. It runs on the frontier model you choose and traces every answer to its sources, so results reconcile under audit.
.webp)
Best CPG Category Management Software (2026): The 6 Platforms Category Teams Actually Shortlist
Category management is evolving from periodic reporting and spreadsheet-driven analysis to continuous, AI-powered decision-making. This guide compares six of the leading category management platforms that CPG teams are actively evaluating in 2026. The comparison examines capabilities across category analytics, assortment optimization, shelf and space planning, retailer collaboration, demand insights, promotional performance, and AI-driven recommendations.