Tellius Kaiya vs. Glean, Hebbia, Snowflake Cortex, and DIY RAG: A Buyer's Guide to Agentic Analytics Across Structured and Unstructured Data
.webp)

Tellius is Decision AI for the enterprise — the intelligence layer connecting your data to your decisions. Kaiya, Tellius's agentic analyst, reasons across warehouse metrics and unstructured evidence in a single governed workflow. This is how that approach holds up against the alternatives buyers evaluate when they need to answer the *why* questions about their business.
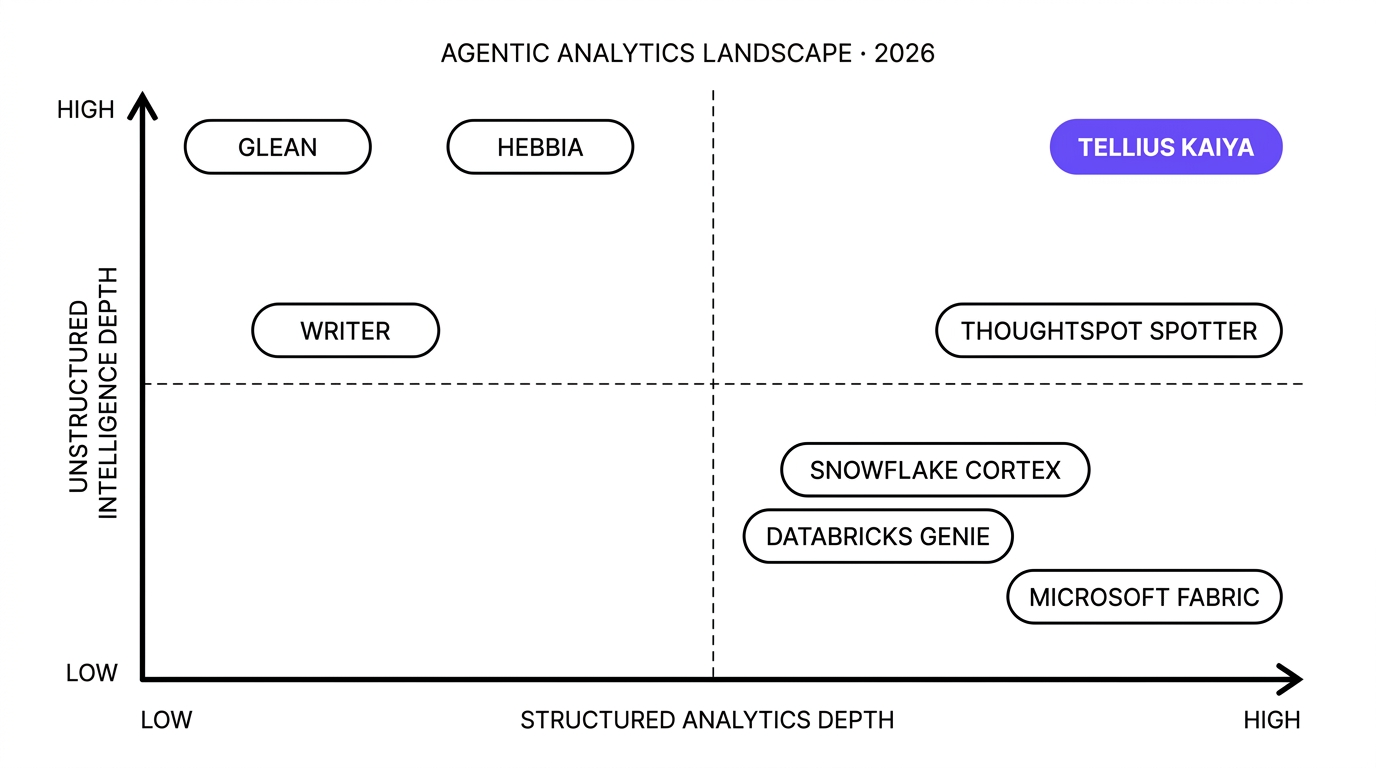
If you're shortlisting an AI analytics platform that reasons across both your warehouse and your documents, you're in a crowded category. The landscape splits five ways: hyperscaler AI (Snowflake Cortex, Databricks Genie, Microsoft Fabric), enterprise search and Work AI (Glean, Sana), document intelligence (Hebbia, Writer, AlphaSense), agentic analytics platforms (Tellius Kaiya, ThoughtSpot Spotter), and DIY RAG stacks built on LangChain, LlamaIndex, Pinecone, and Weaviate.
All of them claim to handle "structured and unstructured data." Most are telling the truth, partially. The question isn't whether they can retrieve a document chunk next to a SQL result. It's whether they can investigate a business problem by connecting governed metrics, ranked drivers, and qualitative evidence in a single workflow.
What follows is how Tellius Kaiya compares to the alternatives. Competitors win in places. The category is still figuring itself out in others. Both get flagged.
What is agentic analytics, and why does structured \+ unstructured matter?
Agentic analytics is the emerging category Gartner formalized in its 2025 and 2026 Market Guide for Agentic Analytics. The premise: AI agents don't just answer natural language questions against a dashboard. They plan multi-step investigations, execute SQL and Python, retrieve evidence, rank drivers, and produce executive-ready findings.
The "structured \+ unstructured" requirement exists because real business questions rarely live in one data type.
Consider a pharma commercial leader asking: "Why did new-to-brand prescriptions for our oncology drug drop 12% in the Northeast last quarter?"
- The structured answer lives in claims data, IQVIA feeds, CRM call logs, and territory assignments.
- The unstructured explanation lives in payer contract amendments, MSL field notes, call transcripts with oncologists, formulary change PDFs, and competitive intelligence briefs.
A BI copilot can show the drop. An enterprise search tool can surface the contract amendment. Neither can connect them into a single explanation with ranked drivers and cited evidence. Closing that gap, between knowing what changed and understanding why, is what agentic analytics platforms are built to do.
How does Tellius Kaiya approach unstructured data differently from standard RAG?
Kaiya's approach to unstructured data has a name: ingest-time structuring. Most "RAG for the enterprise" tools do retrieval-time work. They chunk documents into fixed-size windows, embed them with a general-purpose model, store the vectors in a database, retrieve top-k results at query time, and let an LLM synthesize an answer. The structure, if any, gets imposed on the fly.
Kaiya inverts that. Documents get classified, entity-extracted, and clustered at ingest time, before any query arrives. By the time someone asks a question, the unstructured corpus already behaves more like a structured asset than a pile of text. Here's what happens at index time:
- Domain-aware classification. Every ingested document is classified by industry and document type. A payer contract is treated differently from a clinical study report, which is treated differently from a Gong call transcript.
- Auto-identified entities per document type. The system decides which entities matter for this document before extraction runs. A CSR gets different entity templates than a marketing brief.
- Domain-specific entity extraction. Pharma-aware entities include products, HCPs, competitors, formulary references, and payer entities. CPG-aware entities include retailers, brands, and trade terms. This is not generic NER.
- Semantic clustering into workspaces. Documents are grouped by semantic similarity at ingest, creating document-level context that chunk-level retrieval alone misses.
- Hybrid retrieval across three parallel paths. Every query hits entities, chunks, and workspaces — each using both dense semantic search and BM25 keyword search. Keyword coverage matters in regulated industries where exact product names, molecule IDs, and regulatory terms dominate.
- Metadata filtering. Users can scope queries to specific document types ("only across payer contracts") or user-defined metadata.
- LLM reasoning layer. Synthesis happens across all retrieval signals with citations, grounded in the business semantic layer.
The practical impact: when you ask Kaiya about "formulary pressure on oncology in Q3," it doesn't just find chunks that mention those words. It finds the payer entities affected, the brands impacted, and the territories at risk, then joins those to the structured metrics showing the prescription decline. All of that was structured at ingest time, not improvised at query time.
Vanilla RAG retrieves text. Kaiya structures the unstructured first, then retrieves.
Tellius Kaiya vs. Glean: enterprise search or business performance investigation?
Glean's strength is finding things. Documents, messages, tickets, and files across 50+ SaaS tools, ranked by a personalized Enterprise Graph, with source-system ACLs respected end-to-end. Its Work AI assistants sit natively in Slack, Teams, and email, which is where knowledge workers actually live. If the problem is that nobody can find the latest Q3 board deck in SharePoint, Glean will crush it.
Kaiya isn't trying to solve that problem. It runs Text-to-SQL against warehouses with a governed semantic layer, performs ranked driver analysis to investigate why a metric moved, and reasons across unstructured evidence — call transcripts, payer contracts, MSL notes, field reports — to assemble a holistic picture of the why behind a number. Pharma and CPG entities get extracted inside the retrieval pipeline itself, and Deep Insights continuously investigates metrics instead of waiting for someone to ask. Ask Kaiya "what was NBRx growth by payer tier last quarter with ranked drivers" and you get an explanation grounded in both the warehouse and the documents that explain the warehouse. Ask Glean the same question and you get documents that mention NBRx growth.
The gap is architectural, not a feature on a roadmap. Glean's Conversational BI queries app APIs — Salesforce reports, Databricks dashboards — not warehouse tables with semantic context. The analytical machinery isn't there.
So the choice is straightforward. Glean fits when horizontal knowledge findability is the primary problem and analytics is secondary. Kaiya fits when you need to explain why business metrics changed by joining structured analytics to unstructured evidence, especially in pharma or CPG. In practice, the two tools are often complementary rather than competitive, and several large enterprises run both.
Tellius Kaiya vs. Hebbia: document intelligence or metric-to-evidence investigation?
Hebbia's Matrix is a document intelligence platform built for finance and legal. It raised $130M at a $700M valuation, has processed over a billion pages, and is used by 30%+ of the top 50 asset managers. Its Iterative Source Decomposition (ISD) architecture does multi-step reasoning across thousands of files with full citations.
Where Hebbia wins:
- Exhaustive document analysis at scale (thousands of files in a single workflow)
- Finance and legal due diligence workflows with transparent audit trails
- Tabular document intelligence that extracts structured columns from unstructured corpora
- Deep expertise in regulated finance and legal use cases
Where Kaiya wins:
- Joining document findings to live structured metrics (claims data, sales data, CRM)
- Pharma and CPG domain specialization out of the box
- Continuous metric monitoring with Deep Insights
- End-to-end investigation workflows, not just corpus analysis
Hebbia is the right tool when the use case is analyze this corpus. Kaiya is the right tool when the use case is explain this business outcome. Hebbia can tell you what every payer contract amendment says. Kaiya can tell you which amendments correlate with NBRx movement in the affected territory last quarter.
Choose Hebbia when: the use case is document-heavy corpus analysis (M\&A diligence, legal review, expert interviews) with no mandatory structured analytics dimension.
Choose Kaiya when: you need document findings connected to governed metrics, segments, and business outcomes — especially in a pharma commercial or CPG analytics context.
Tellius Kaiya vs. Snowflake Cortex Agents: warehouse-native plumbing or business-ready investigation?
Snowflake Cortex Agents went GA at BUILD 2025 and is the most complete warehouse-native "structured + unstructured" offering. Cortex Analyst generates SQL with 90% accuracy on verified Semantic Views per Snowflake's own benchmarks. Cortex Search outperforms Azure AI Search on hybrid retrieval benchmarks. Document AI with Arctic-TILT handles complex tables and scanned PDFs well.
Where Snowflake Cortex wins:
- Data never leaves Snowflake — the governance perimeter stays intact
- Strong document parsing with Arctic-TILT for complex tables and scanned PDFs
- Hybrid retrieval with a built-in cross-encoder reranker
- Tight integration with Unity-style governance via Horizon Catalog
Where Kaiya wins:
- Semantic layer is generated conversationally by Kaiya Architect, not hand-authored in YAML
- Domain entity extraction for pharma and CPG at index time — Cortex does generic NER
- Deep Insights provides continuous ranked driver analysis, not reactive chat
- Cross-warehouse support (Snowflake, BigQuery, Redshift, Databricks, Postgres, MySQL)
- Predictable pricing — Snowflake's token \+ serving-compute model has produced documented five-figure single-query bills
Cortex is solid infrastructure. Hand Snowflake a clean YAML Semantic Model and Cortex Analyst will answer well. The catch is who writes the YAML. In practice, it's a Snowflake-certified engineer or partner SI spending weeks per domain. Kaiya Architect does this conversationally in under 30 minutes.
Choose Snowflake Cortex when: you're fully standardized on Snowflake, you have an engineering team that can hand-author and maintain Semantic Views, and you want minimal data movement.
Choose Kaiya when: you need cross-warehouse analytics, pharma or CPG semantic layers out of the box, and a business-user-ready investigation experience instead of an engineering platform.
Tellius Kaiya vs. DIY RAG (LangChain \+ LlamaIndex \+ Pinecone \+ Vanna)
Every three months, a well-funded engineering team at a Fortune 500 says: "We can build this ourselves." Sometimes they're right. More often, they learn why they weren't.
What a DIY stack typically looks like:
- Orchestration: LangChain, LangGraph, or LlamaIndex
- Document parsing: Unstructured.io OSS, LlamaParse, or RAGFlow's DeepDoc
- Embeddings: OpenAI text-embedding-3, Cohere Embed v3, or Voyage
- Vector database: Pinecone, Weaviate, Qdrant, Milvus, or pgvector
- Text-to-SQL: Vanna AI, SQLCoder, or DefogAI
- Reranking: Cohere Rerank v3 or BGE reranker
- Evaluation: Ragas, LangSmith, or TruLens
- Governance: Custom RBAC, row-level security, document ACL sync
Where DIY wins:
- Full architectural control for airgapped or highly regulated environments
- Hyper-narrow use cases (one document type, one team, one workflow)
- When the stack itself is strategic IP being sold externally
- Teams with mature ML platform engineering who need unique retrieval behaviors
Where DIY breaks down in production:
- Permissions sync. Enterprise docs, CRM records, call transcripts, and warehouse rows all have different access models. Keeping them in sync is a full-time job.
- Metric consistency. RAG can cite documents, but it has no idea what "NBRx" or "gross-to-net" actually means in your governance layer.
- Join logic. Connecting an MSL report to claims data requires reliable grain, entity resolution, and time alignment.
- Evaluation drift. Without continuous evals on production traffic, retrieval and synthesis quality decay silently as document corpora grow and user query patterns shift. Most teams discover this only after a business user catches a wrong answer.
- Freshness. Document updates cascade into re-chunking, re-embedding, re-indexing — usually manual.
- Business-user UX. Business teams don't use notebooks. Building a packaged workflow is different from building a chatbot.
MIT's NANDA "State of AI in Business 2025" research, published in August 2025, found that roughly 95% of enterprise generative AI pilots deliver no measurable P&L impact. The demo is easy. The governed, evaluated, permissioned, business-user product is a 12-month engineering program.
Choose DIY when: you have a mature ML platform team, airgapped deployment requirements, or one narrow use case where the engineering investment is justified.
Choose Kaiya when: you need a governed analytics agent with a pharma or CPG semantic layer, continuous Deep Insights, permission-aware retrieval, and a business-user UX — shipping in weeks, not years.
What about ThoughtSpot Spotter, Writer, Databricks Genie, and Microsoft Fabric?
A few more comparisons worth being direct about:
ThoughtSpot Spotter 3 is the closest direct peer to Kaiya in agentic analytics. Spotter 3 launched native structured + unstructured blending in late 2025, and the Spotter for Healthcare and Life Sciences solution followed. The category convergence is real. The architectural difference is where the structuring happens: Spotter 3 blends structured and unstructured at query time; Kaiya runs ingest-time structuring with pharma and CPG entity extraction baked into the index, then layers continuous Deep Insights on top for root-cause monitoring rather than reactive chat. The HLS solution is new and will take time to ruggedize against the depth of pharma semantics Kaiya ships out of the box.
Writer.com built an agentic enterprise AI platform anchored in its graph-based Knowledge Graph and the specialized Palmyra Med and Palmyra Fin LLMs. Writer's own documentation acknowledges that Knowledge Graph is not suited for exhaustive numeric queries. For content generation and document synthesis in pharma or finance, Writer is strong. For analytics that joins documents to warehouse metrics, it doesn't compete.
Databricks Genie with Agent Bricks is the closest Lakehouse-native competitor. Genie works well for Databricks-standardized shops, but Genie spaces typically require weeks of curation, including value dictionaries and SQL snippets per space. Agent Bricks is still in Beta. Kaiya Architect generates semantic layers conversationally without this overhead.
Microsoft Fabric \+ Power BI Copilot is the default for Microsoft-standardized enterprises. Fabric Data Agents and the new Fabric IQ Ontology are preview features, not GA. Azure AI Search indexes require separate setup. Kaiya ships pharma and CPG semantics out of the box; Microsoft requires customer engineering to match.
Which agentic analytics platform should you choose? A decision framework
Here's a decision framework based on where each platform actually wins:
Kaiya's sweet spot is specific: commercial performance investigation in regulated or data-rich verticals where the answer requires ranked drivers from structured data plus cited evidence from unstructured content — in a single governed workflow.
Capability comparison at a glance
The bottom line
No single tool is the right answer for every enterprise.
If your problem is finding knowledge across SaaS apps, Glean wins. If it's analyzing a document corpus, Hebbia wins. If you're all-in on a single hyperscaler and have the engineering team to hand-author semantic models, Cortex or Genie may win. If you have unique requirements and a mature ML team, DIY may win.
If your problem is explaining why commercial metrics changed, and the answer lives across claims data, CRM notes, payer contracts, call transcripts, and market context, Kaiya is built for that workflow.
Tellius is Decision AI for the enterprise — the intelligence layer connecting your data to your decisions. Kaiya's defensible position inside that frame is specific: agentic business investigation for pharma and CPG that combines governed warehouse analytics, continuous root-cause monitoring, ingest-time structured unstructured intelligence, and a conversational semantic layer builder, in a single governed platform. Kaiya reasons across your structured and unstructured data with domain knowledge, runs as always-on Missions that pursue your objectives, and ships finished work into the workflows where decisions actually get made.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!


RAG (retrieval-augmented generation) retrieves relevant text chunks and lets an LLM synthesize an answer. Agentic analytics goes further: it plans multi-step investigations, executes SQL and Python against governed data, ranks drivers, retrieves qualitative evidence, and produces executive-ready findings. RAG answers questions about documents. Agentic analytics explains business outcomes.
Ingest-time structuring is the approach Tellius Kaiya uses to handle unstructured data. Documents are classified by industry and type, entity-extracted with domain-specific schemas (pharma, CPG), and semantically clustered at ingest time — before any query arrives. Standard RAG defers all structure to retrieval time (chunk, embed, top-k, synthesize). Ingest-time structuring inverts that: by the time a question gets asked, the corpus already behaves more like a structured asset than a pile of text, which is what lets Kaiya join document findings to warehouse metrics in a single workflow.
For technically sophisticated teams willing to hand-author semantic layers (YAML Semantic Views in Snowflake, Metric Views in Databricks) and invest in curation, yes — they can handle many use cases. For business-user workflows, pharma/CPG semantic depth, and continuous root-cause investigation, dedicated agentic analytics platforms like Tellius Kaiya deliver faster time-to-value.
In practice, they solve adjacent problems. Glean is the leader for enterprise knowledge search across many SaaS apps. Kaiya is built for explaining why business metrics change by combining structured analytics with unstructured evidence. Many enterprises use both.
Kaiya's domain-specific entity extraction identifies pharma entities — products, HCPs, competitors, formulary references, payer entities — at ingest time. This structured metadata is used at retrieval time to enable queries that join document findings to claims data, CRM records, and warehouse metrics. Generic RAG and generic NER approaches don't have this domain specialization.
DIY makes sense in three specific scenarios: airgapped environments where no SaaS is acceptable, hyper-narrow use cases where the engineering investment is contained, or when the RAG stack itself is strategic IP. For broad enterprise analytics across pharma, CPG, or commercial use cases, platform approaches deliver faster time-to-value with lower total cost of ownership.

Best AI Analytics Platforms in 2026: 12 Tools Compared for Deep Insights, Governance, and Agentic Capabilities
This guide compares 12 AI analytics platforms in 2026 across the capabilities that actually separate “chat with your warehouse” from real analytical automation: governed conversational analytics, automated deep insights (root cause decomposition + ranked drivers), proactive monitoring, persistent business knowledge and context, industry specificity, agentic workflow orchestration, and total cost of ownership. It explains the maturity ladder from reactive Q&A to always-on agents that detect anomalies, investigate why metrics changed, and deliver executive-ready narratives and recommendations—then profiles where each platform fits (and where “agentic” claims don’t match reality).