AI Agents for Pharma Commercial Teams: The 2026 Field Guide to Use Cases, Vendors, and What's Actually Real


AI agents for pharma commercial teams are software systems that autonomously plan and execute multi-step commercial work, from preparing reps and targeting HCPs to drafting compliant content and investigating performance, all on governed pharma data.
TL;DR:
- The market is a stack, not a list. Engagement agents and intelligence agents do different jobs, and they complement each other rather than compete.
- 2025-26 is the inflection point, but read the fine print: most published proof is vendor-reported.
- The buyer question that matters isn't what an agent can do. It's whether the agent gives the same answer twice.
- Governed, deterministic autonomy is the credible pattern. A generic LLM with a prompt is not.

What's possible today: use cases and the vendor landscape
What "AI agent" actually means here (and what it doesn't)
The first wave of enterprise AI answered questions. Chatbots and copilots took one prompt at a time, returned one response, and waited. A human read every answer, caught the misses, and supplied whatever context the model lacked. Agents work differently. They plan and execute multi-step commercial tasks end to end, from pulling the data to producing the deliverable, without a person steering each step.
The formal version of this is a capability ladder. Predictive AI scores and recommends (next-best-action models, HCP propensity scores). Generative AI drafts and summarizes (call notes, email copy, content variants). Agentic AI executes multi-step chains. It decides what to investigate, runs the steps, checks its own intermediate results, and hands back a finished output rather than a suggestion.
One caveat belongs this early in the piece: most of what's marketed as an "agent" isn't one. Gartner calls the practice "agent washing" and estimated in June 2025 that of the thousands of vendors claiming agentic capability, only about 130 were genuinely agentic (Gartner, June 2025). A rebranded chatbot with function-calling is still a chatbot.
Agentic AI vs generative AI in pharma
Generative AI in pharma commercial work produces content. You get a draft email, a summarized call transcript, a first-pass detail aid. Agentic AI produces outcomes, like a prioritized call plan with the reasoning attached, a root-cause investigation of a share decline, or a pre-call brief assembled from CRM, claims, and formulary data before anyone asked for it. The generative layer is one tool the agent uses along the way rather than the thing itself.
The distinction sounds academic until an agent's output drives a targeting decision or lands in front of an MLR reviewer. A chatbot's mistakes got caught because a person read every answer before acting on it. An agent's output gets compared period over period, audited, and acted on, sometimes with nobody in between. What that demands of the technology is the harder question.
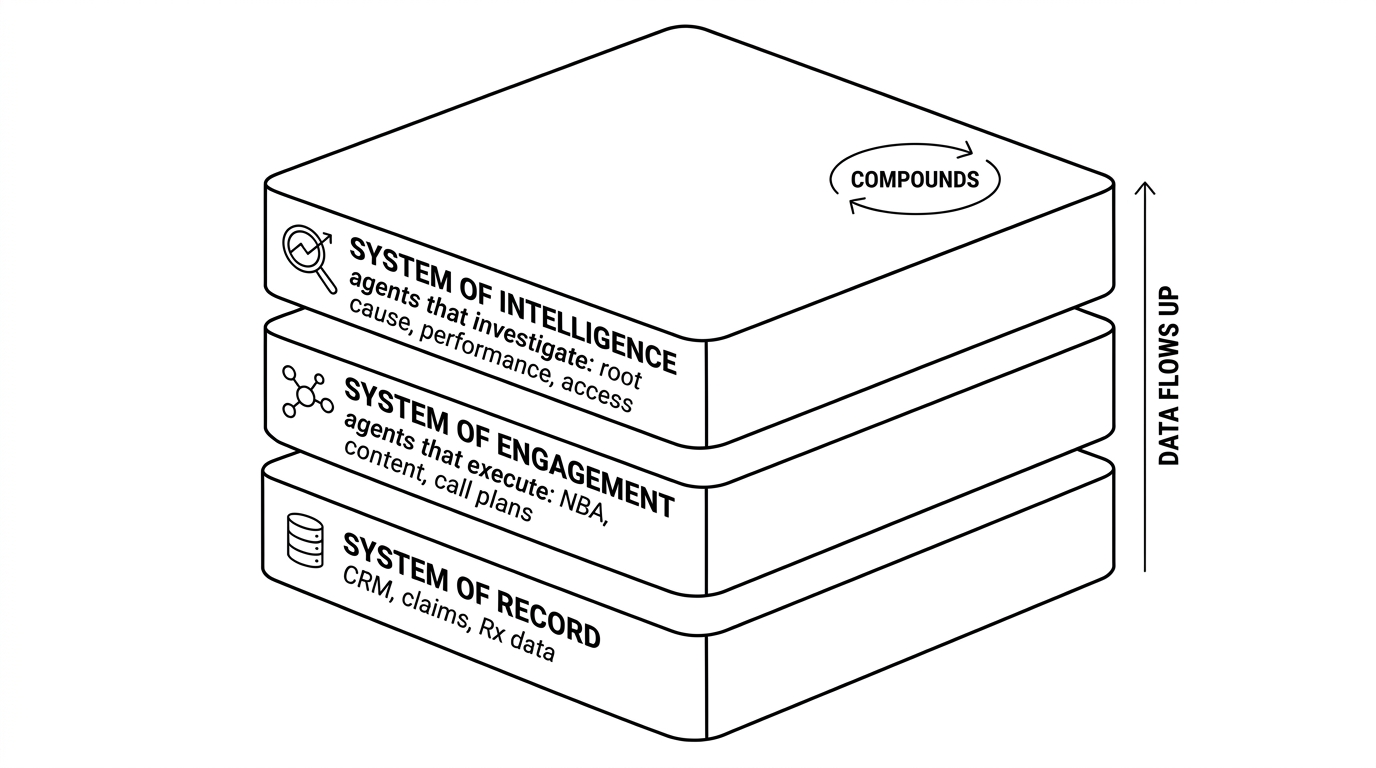
The market is a stack, not a list
Most coverage of AI agents in pharma presents a flat list of vendors. The market doesn't actually work that way. It splits into two camps that do different jobs and sit at different layers of the commercial stack.
These camps are complementary, not competitive. Intelligence agents sit on top of the data engagement agents generate. Every call logged, every email sent, every sample dropped becomes input for the layer that explains performance.
There's an emerging label for the top of this stack. Some of the market has started calling it a "system of work," meaning agents that complete the work rather than just answering questions about it. Buyers should know who coined the term, though. Salesforce calls it an "agentic operating system," and EY and SAP push their own variants. The neutral frame, and the one this guide uses, is the older progression from system of record to system of engagement to system of intelligence.
Whatever the label, one property separates the top layer: does it compound? A stateless agent re-derives context on every task and resets to zero. A compounding system accrues resolved metric definitions, prior investigations, and the decisions made on them, so each cycle gets cheaper and sharper. Even the engagement-camp vendors concede the point; their own positioning describes agents inheriting a unified, governed organizational memory.
Use cases by function: where agents work today
Here's what agents actually do for each commercial function, with an honest read on how mature each use case really is. The last column rates maturity rather than naming vendors. This part is about the work itself.
Sales force effectiveness. The most deployed category. Pre-call preparation that used to consume a rep's evening (pulling prescribing history, recent calls, and formulary status for tomorrow's eight HCPs) is now assembled by agents overnight, and voice-captured call notes write structured data back to CRM. Coaching agents score role-play readiness against brand strategy. Verdict: real today.
HCP targeting, NBA and omnichannel orchestration. Next-best-action engines predate the agent era. What's new is agents that close the loop, adjusting targets and channel mix continuously instead of waiting for the annual refresh, and attaching the why to every recommendation so field teams actually trust them. Verdict: real and maturing.
Commercial analytics and root-cause investigation. This is the layer that answers the Monday-morning question. Take a concrete one: a brand manager asks why TRx (total prescriptions) fell 12% this quarter. An investigation agent decomposes the decline across regions, payer channels, and prescriber deciles in one pass. It isolates two thirds of the drop to a pair of plans that moved the brand to non-preferred status in February, flags the prior-authorization spike that followed, identifies the high-decile HCPs whose prescribing fell fastest, and drafts the summary for Monday's call. Tellius demonstrates this pattern in production: the 12% question goes in, the decomposed, sourced answer comes out. Verdict: real today, but reproducibility is the differentiator — and that's where the harder questions start.
Compliant content and MLR. Agents draft compliant variants and pre-screen claims against approved references, cutting review queues. Nobody serious is proposing that agents approve promotional content, and the credible vendors design accordingly. Verdict: early, and properly governance-gated.
Territory, call-plan and incentive planning. Quietly mature. Alignment scenarios, call-plan generation, and IC modeling are structured optimization problems agents handle well, and the planning cycle compresses from weeks to days. Verdict: real and established.
Market access and payer intelligence. Agents here watch formulary positions, flag PA spikes before they show up in lagged Rx data, and quantify what an access barrier costs in volume. The hard part is data plumbing; where the feeds exist, this category delivers. Verdict: real and maturing.
What this looks like in practice: the art of the possible
The table says what's real. It doesn't say what it feels like when it's running. The shift isn't a faster chatbot in the corner of a dashboard — it's finished work waiting for you when you open the screen. Here are two mornings, two roles.
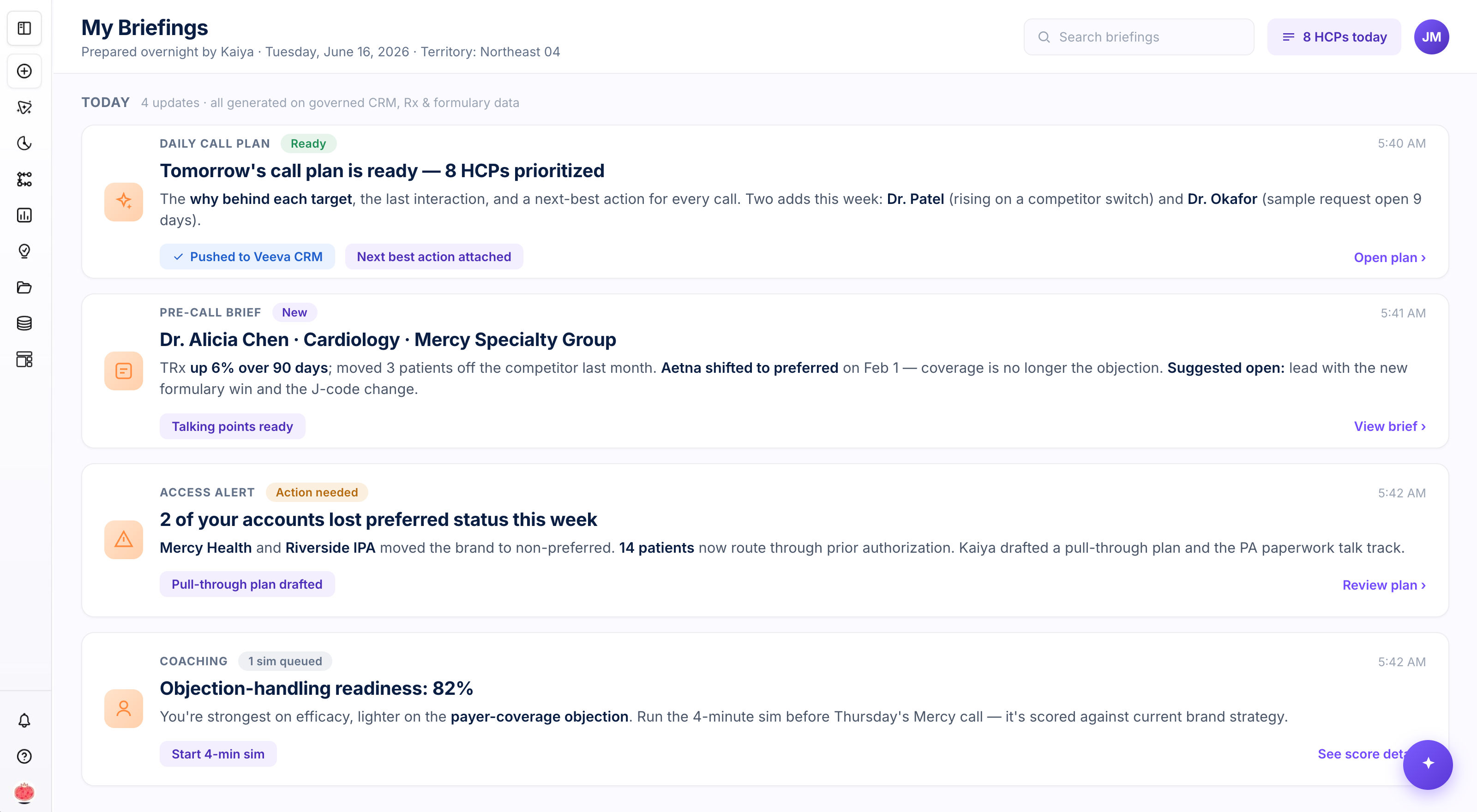
For the rep: the briefing is already done
Pre-call prep used to be an evening of tab-switching — prescribing history in one system, last call notes in another, formulary status in a third, for tomorrow's eight HCPs. Now the rep opens a single feed. Overnight, agents built tomorrow's prioritized call plan with the why behind each target and a next best action, and wrote it back to Veeva. Each HCP has a pre-call brief — recent Rx trend, last interaction, a formulary change that flips the conversation. An access alert flags the two accounts that just lost preferred status, with a pull-through plan already drafted. A coaching nudge points at the one objection worth practicing before Thursday. None of it was requested. It was waiting.
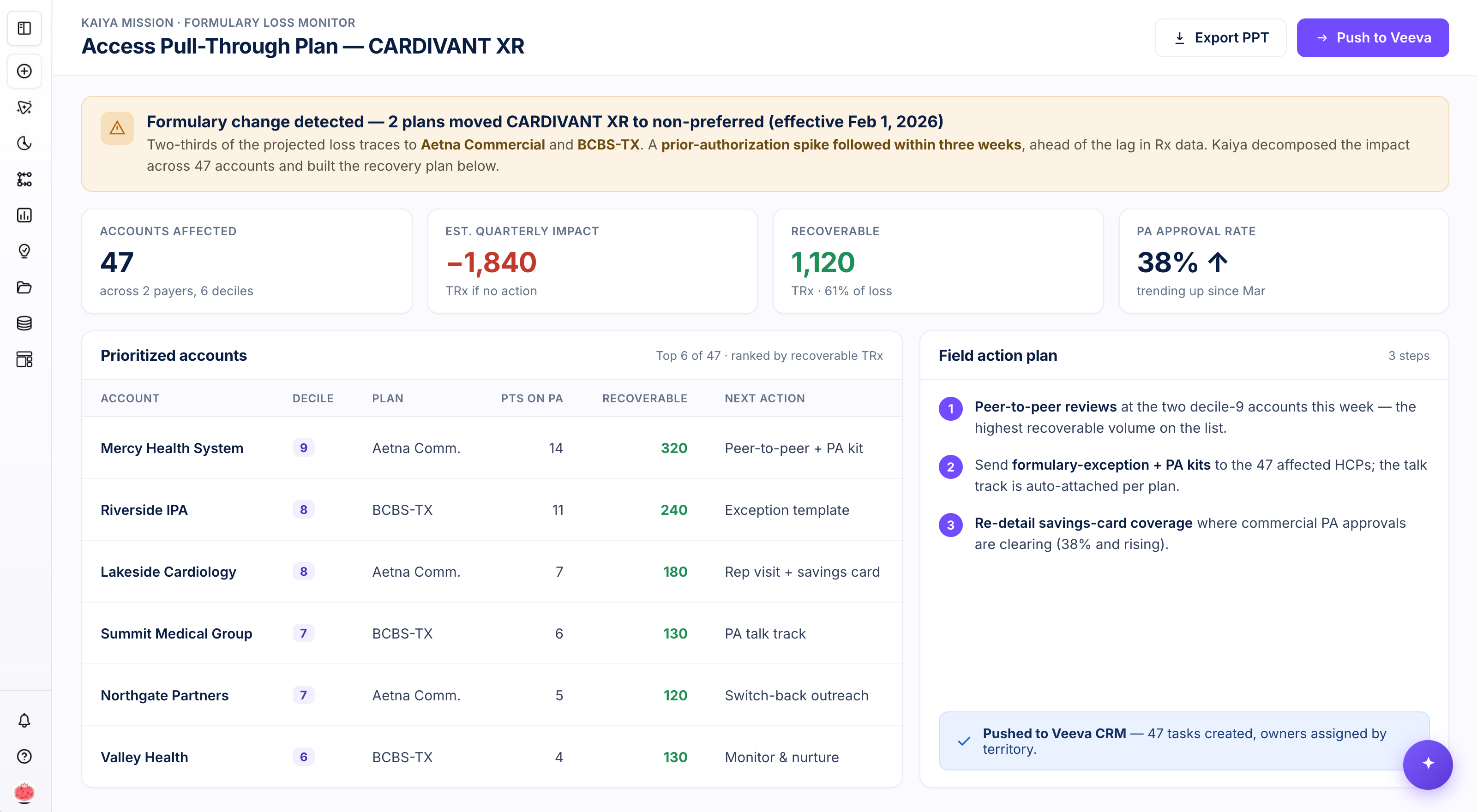
For the access team: a formulary loss, caught and costed
When two plans move a brand to non-preferred, the damage usually surfaces in Rx data weeks later, after the quarter is already bleeding. An access agent watches the formulary feeds directly. The moment the change lands, it decomposes the impact across every affected account, isolates the share of the loss that traces to specific payers, costs the quarter in lost TRx, ranks the accounts by what's actually recoverable, drafts the field action plan, and pushes the tasks into Veeva with owners assigned by territory. The brand manager's version of the same investigation — the "why did TRx fall 12%" decomposition from the table above — arrives as a finished deck before Monday's call, not a blank page for an analyst.
What makes it real: reliability, memory, and governance
So far the through-line has been the shift that matters: from chat to work. The moment AI stops answering a human and starts doing audited, decision-driving work, three criteria become non-negotiable. Reliable today: does it hold up on the second run? Compounding over time: does it get smarter, or reset to zero? Bounded by governance: who stays on the high-stakes calls? Chat tolerated drift and amnesia. Work doesn't.
What's real vs. what's hype
The adoption numbers are genuinely large. McKinsey estimates 75-85% of pharma workflows contain tasks agents could automate or enhance, potentially freeing 25-40% of capacity (McKinsey, 2025). An MIT Technology Review Insights survey with Globant found 73% of pharma organizations planning, piloting, or deploying agentic AI (MIT Technology Review Insights / Globant, 2025). The pressure behind those numbers is structural, too. With field access to HCPs down to roughly 45%, from 60% just eighteen months earlier, commercial teams are being asked to do more with fewer touchpoints (Veeva Pulse, 2024).
Now the other column. Gartner predicts more than 40% of agentic AI projects will be canceled by the end of 2027, citing cost, unclear value, and inadequate risk controls (Gartner, June 2025). And the bottom-line impact stays thin: in McKinsey's 2025 State of AI survey, most organizations report no material enterprise-level EBIT impact from generative AI yet, with only about 6% qualifying as high performers (McKinsey State of AI, 2025).
The most useful evidence comes from independent benchmarks, the rare numbers no vendor's marketing team wrote. On CRMArena-Pro, a Salesforce-built benchmark of realistic CRM tasks, leading agents completed roughly 58% of single-turn tasks, falling to about 35% in multi-turn settings (Salesforce AI Research, 2025). On TheAgentCompany, Carnegie Mellon's simulated-workplace benchmark, the best agent fully completed about 24% of tasks (CMU, 2025). On SCUBA, a benchmark of real enterprise analytics workflows, open-source agents completed under 5% of tasks zero-shot, and even closed-source models reached only about 39% (Salesforce, 2025).
Put those three numbers side by side: left to its own devices, an agent is inconsistent. Inconsistency, not incapability, is what blocks adoption. The same system that dazzles in a demo fails quietly on the second, slightly different run.
One transparency caveat applies to every vendor number in this piece. Named deployers are public, but the KPIs are rarely independently audited. Treat vendor-reported figures accordingly.
The anatomy of a commercial agent: five layers and a governance wrapper
The benchmarks show what an under-built agent fails at. It's worth asking what a system that doesn't fail would actually be made of. An agent you can run a brand on isn't a model with a prompt. It's a stack, and each layer does a distinct job:
- Governed data and a semantic layer. CRM, Rx and claims, and formulary data, unified under one trusted view with locked metric definitions. This is the foundation every layer above inherits — including what "share" or "TRx" even means.
- Context and memory. Persistent, governed memory that holds resolved definitions, prior investigations, and the decisions made on them, so each run inherits the last instead of starting from zero.
- Reasoning and decision. The planning layer. It decomposes the question into steps, then validates its interpretation and locks the specification before anything executes.
- Execution. Runs the multi-step chain — query, analyze, generate — and checks its own intermediate results instead of handing back the first draft it produces.
- Delivery and action. Turns the result into a finished brief, deck, or alert and delivers it where the work happens: the rep's inbox, the brand review, Veeva, Slack.
All five sit inside a single governance perimeter — MLR-aware design, HIPAA minimum-necessary limits, 21 CFR Part 11 audit trails, and a human on every high-stakes action. The two layers that separate a real platform from a thin wrapper are the ones in the middle: memory and reasoning. The rest of this section is really about those two — determinism in the reasoning layer, compounding in the memory layer, and the governance that makes both safe.

Reliable and compounding: two views of one architecture
The benchmarks above establish the problem. What follows are architectural requirements any buyer should demand, not features of one product. There are two movements here, determinism within a workflow and compounding memory across workflows, and they turn out to be the same idea (persistent, governed state) viewed at two time horizons.
Reliable today: why agents drift, and what fixes it
The root cause of agent inconsistency is under-specification rather than a flaky model. Large language models are probabilistic, and when a user states a task in plain language, the statement always leaves gaps. The model fills each gap with a different but equally reasonable interpretation on each run. Same question, same data, different answer, and nobody did anything wrong.
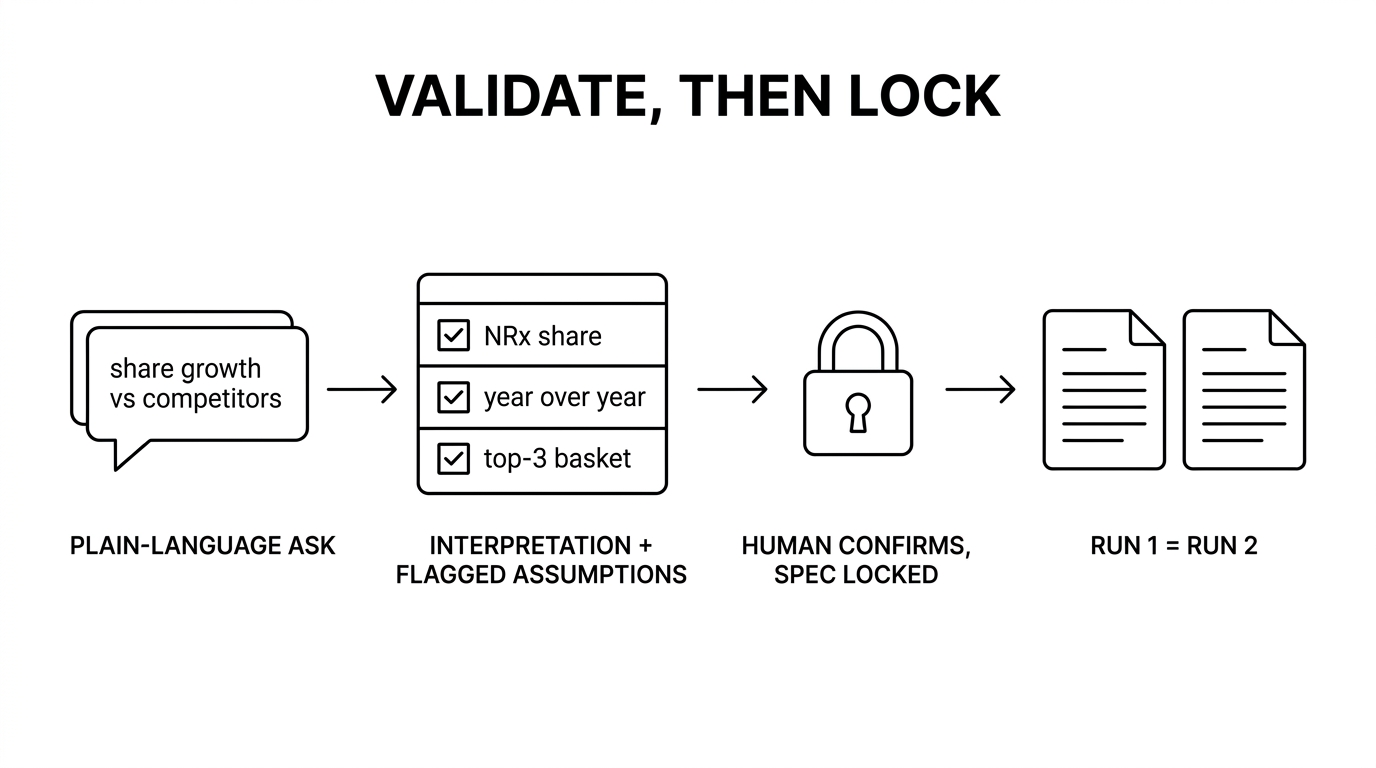
An ordinary pharma question hides more silent decisions than anyone notices on a first read. Take "How is our share growth versus competitors this quarter?" TRx share or NRx share? Versus the prior quarter, or the same quarter last year? Against the full therapeutic class, or the three competitors the brand team actually watches? Each is a defensible judgment call, and changing any one of them between runs moves the answer while the data sits still.
The fix is older than the hype cycle. Data engineers solved reproducibility decades ago with the DAG, a directed acyclic graph of explicit, hard-coded steps. It's reliable, and it's also out of reach for the business user who just wants to ask the share question. The emerging answer keeps the conversational front door and borrows the DAG's spine. Call it validate-then-lock. The system translates the request into a structured interpretation, shows it back, and flags every assumption it made (NRx share, year over year, promoted basket). A human corrects any of them in seconds. Then the system locks the specification and runs that. The math comes from a fixed spec, not a fresh generation. Conversational to build, deterministic to run.
Litmus test #1: does it return the same answer twice? If a workflow can't reproduce its own output across runs, it can't be audited, it can't support period-over-period comparison, and it shouldn't be driving decisions. This is the failure mode the independent benchmarks expose.
Going deeper: [Why AI Workflows Give Different Answers Every Time, and How to Make Them Deterministic].
Compounding over time: why governed memory beats statelessness
Now run the clock forward. Determinism keeps a single workflow from drifting. Compounding memory carries the results forward, so the resolved definitions, the prior investigations, and the decisions made on them persist instead of being re-derived from scratch on every task.
The difference shows up in the economics. A stateless agent starts at zero on every run: same cost, same blind spots, forever. A system with durable memory makes the next investigation cheaper and more contextual. Once "share growth = NRx share, year over year, top-three basket" has been resolved and locked, every future run inherits it. The locked specification from earlier is itself a unit of this memory. Determinism and compounding aren't two features; they're one architecture at two time scales.
One qualifier carries the weight here: the memory has to be governed. A trusted, governed view of enterprise data separates memory that accrues context from memory that quietly accumulates errors and leaks privileged information across teams. The engagement-camp vendors say the same thing in their own language, which suggests this is a category requirement rather than one camp's talking point.
Litmus test #2: does it get smarter the more you use it, or start from zero? A system that can't remember what it resolved last quarter can't be the backbone of recurring commercial work.

Governance: why "generic GenAI with a prompt" isn't enough
In pharma, the regulatory perimeter is the design constraint. FDA fair-balance requirements govern what promotional content can claim. HIPAA's minimum-necessary standard limits what patient-adjacent data an agent should ever touch. 21 CFR Part 11 sets the bar for electronic records and signatures. GDPR Article 22 restricts fully automated decisions with significant effects on individuals. NIST's AI Risk Management Framework is becoming the de facto scaffold for enterprise AI controls.
The pattern that survives contact with all of this is bounded autonomy. Agents prepare, propose, investigate, summarize, and route. Humans approve the high-stakes actions, meaning promotional claims, privacy-sensitive decisions, and validated-record changes. The market signal points the same direction, with leaders converging on MLR-aware design rather than treating compliance as a bolt-on.
Governance also makes compounding memory safe. Memory pays off only because it's governed; without that, a system compounds errors as efficiently as it compounds context. Reliability, memory, and governance interlock: a system you can run a brand on is reliable by design, compounding by architecture, and bounded by control.
How to adopt: a staged roadmap
The credible adoption path has five stages, and the ordering is most of the advice:
- Foundation. Governed data, a semantic layer that fixes metric definitions, audit infrastructure.
- Assistive. Agents prepare and summarize; humans drive every decision.
- Decisioning. Agents recommend with reasoning attached; humans approve.
- Investigation. Agents autonomously decompose performance questions on governed data.
- Scale and governance. Recurring agentic workflows under continuous monitoring and audit.
Data readiness and controls come first, autonomous analytical work comes last, and skipping stages is how projects end up in Gartner's 40%.
The bottom line
The opening distinction still holds. Engagement agents and intelligence agents do different jobs at different layers, and a buyer who keeps that straight will read every vendor pitch more clearly. What's changed underneath is that possibility is now table stakes. Every vendor demo shows an agent doing something impressive. The frontier is whether it does the same thing twice, and whether run two hundred is smarter than run one.
Possibility doesn't compound; memory does. The durable advantage sits wherever governed memory accrues, and right now that's the autonomous investigation layer, the under-served and highest-bar part of the stack, where the architecture that makes an answer reproducible also makes the next answer cheaper.
If you're evaluating that layer, hold every candidate to the two litmus tests: same answer twice, smarter over time.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!


An AI agent for pharma commercial teams is a software system that autonomously plans and executes multi-step commercial work, from preparing reps and targeting HCPs to drafting compliant content and investigating performance, on governed pharma data. Unlike a chatbot, it completes tasks rather than answering one question at a time.
Generative AI produces content such as drafts, summaries, and variants. Agentic AI produces outcomes. It plans a multi-step task, executes it, and delivers a finished result such as a call plan, an investigation, or a report. Agents typically use generative models as components, but the autonomy and end-to-end execution are what make them agents.
The proven use cases are pre-call briefs assembled overnight from CRM, prescription, and formulary data; post-call voice capture that writes structured notes back to CRM; and coaching simulations that score readiness. These are deployed at scale today, not pilots.
Adoption is real. An MIT-Globant survey found 73% of pharma organizations piloting or deploying agents (2025). But most published KPIs are vendor-reported, and independent benchmarks show agents completing only 24-58% of realistic enterprise tasks unassisted. The honest answer: proven in specific functions under governance, overstated in general.
Because plain-language requests are under-specified, and a probabilistic model fills the gaps differently on each run. The fix is validate-then-lock: the system shows its structured interpretation, a human confirms it, and the locked specification rather than a fresh generation is what executes. Same spec, same answer.
Most are stateless today, so every run re-derives context at the same cost with the same blind spots. Systems built on governed memory persist resolved definitions and prior investigations, and each run inherits the last. Stateless agents cost the same every run; systems with governed memory get cheaper and sharper with use.
Apply two litmus tests. Reproducibility: does it return the same answer to the same question twice? Compounding: does it get smarter with use, or reset to zero? Then ask for independent evidence. Benchmarks like CRMArena-Pro and TheAgentCompany show why a vendor demo and a second run are different things.
The credible pattern is bounded autonomy: agents prepare, propose, investigate, and route, while humans approve promotional claims, privacy-sensitive actions, and validated-record changes. Look for MLR-aware workflow design, audit trails on every output, and adherence to frameworks like NIST AI RMF and 21 CFR Part 11.
The market is a segmented map rather than a single list: CRM and engagement suites (Veeva, Salesforce), orchestration and NBA (PharmaForceIQ, ODAIA), data and analytics services (IQVIA, ZS), planning (Axtria), MLR content, coaching (Quantified), and autonomous commercial analytics. For scored, platform-level comparisons, see the linked listicles in this guide.
.webp)
Best AI Platforms for Pharma Commercial Analytics in 2026: 11 Platforms Compared
This guide compares the 11 best AI platforms for pharma commercial analytics in 2026, evaluating how each supports brand performance, market access, patient analytics, field force effectiveness, incentive compensation, and omnichannel engagement. It highlights a key shift in the market: traditional BI and SFE tools focus on reporting what happened, while newer AI platforms differentiate by investigating why performance changed. The post breaks down core capabilities like root cause analysis, data integration, governance, and agentic workflows—helping pharma teams identify which platforms can deliver faster, more actionable insights across commercial operations.