The AI Platform for Your Company’s Data and Knowledge
Empower anyone to uncover insights, automate workflows, and drive actions with AI.













What Tellius is All About
Go beyond static dashboards to get instant answers, deep insights, and agentic flows that drive outsized outcomes.


Faster Insights, Unstoppable Impact
ChatGPT-like Interface to all your enterprise data
Interact with enterprise data conversationally, facilitating better and faster decision-making.

Shortcut to WHY with AI Insights & Narratives
Analyze billions of datapoints to get to the hidden root causes and key drivers, saving lots of time

Put GenAI to Work
Use & build AI agents and agentic flows that transform data into immediate actions, effectively creating an AI analyst for everyone


Answer + Act on Any Enterprise Question
& reporting
code-based predictive analytics
Conversations, Insights + Agentic Flows
Empower your people. Accelerate work.
Every Quarter.
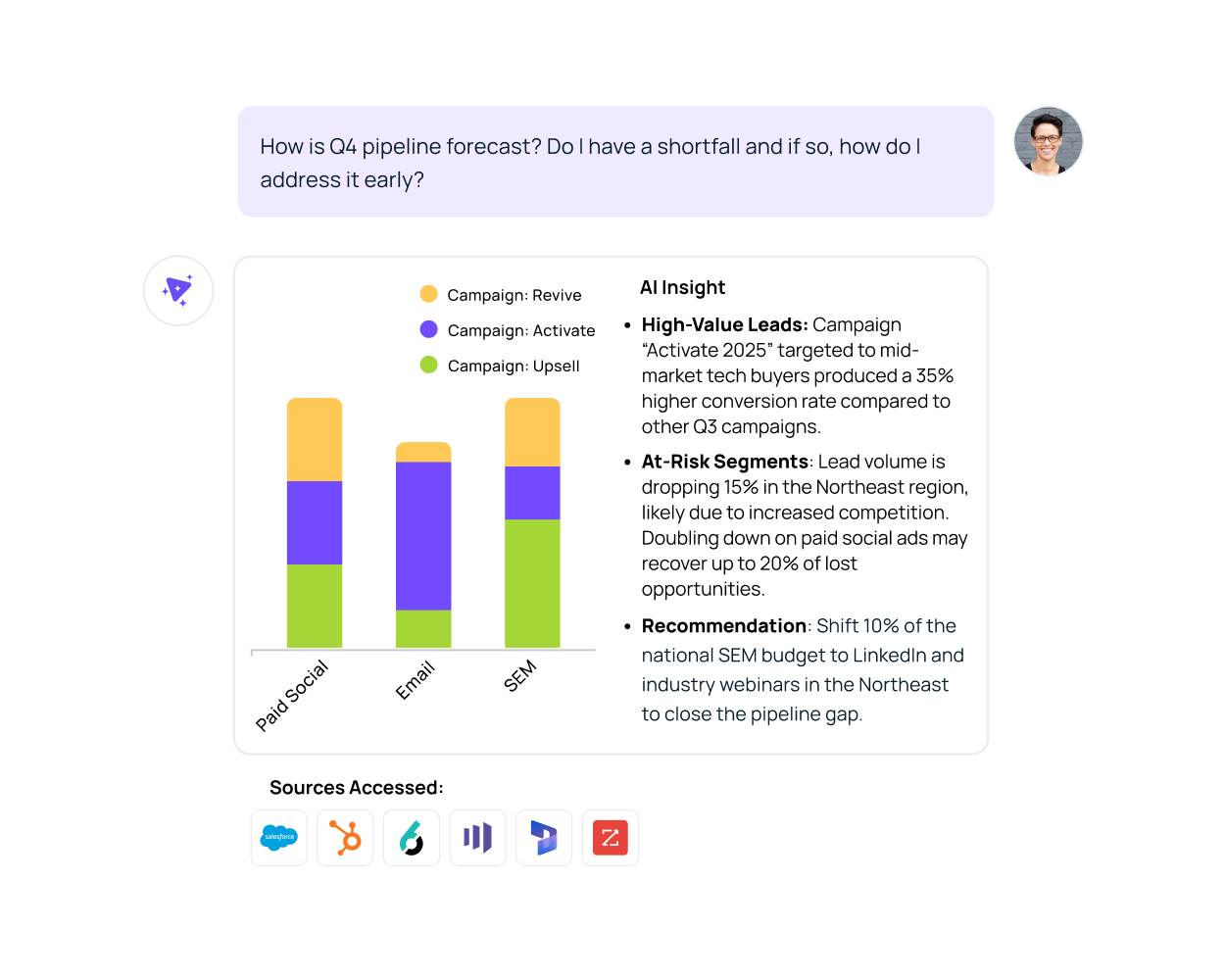
Supercharge deal velocity and accelerate revenue with AI-powered RevOps Intelligence. Spot hidden risks, enable every seller, and trigger next-best actions through by unifying your CRM, field activity, and revenue tools through an intuitive conversational interface.


Unify all your data, automate variance analysis, deliver unstoppable forecasts, and uncover the ‘why’ —without the spreadsheet chaos.


Your missing intelligence layer—unifying data, metrics, & knowledge—into a conversational insights engine that empowers true self-service analytics bridging the gap between questions and actionable insights.


Integrate all your supply chain data, automate demand forecasting, uncover bottlenecks, and enhance efficiency—without the guesswork or delays.


Consolidate all your marketing data, automate campaign optimization, uncover customer insights, and drive impactful strategies—without the manual effort or uncertainty.

Unleash the full power of data
to insights











Breakthrough Ideas, Right at Your Fingertips
Dig into our latest guides, webinars, whitepapers, and best practices that help you leverage data for tangible, scalable results.

Introducing Tellius AI Agents
Tellius AI Agents and AgentComposer transform business analytics by automating complex multi-step analysis through specialized autonomous agents. Unlike generic chatbots or RPA tools, these agents leverage your enterprise data and business context to deliver deep insights across sales, marketing, finance, and manufacturing—turning questions into actions in minutes instead of days. With no-code agentic workflows, organizations can achieve 100X productivity gains and continuous, data-driven decision making.

AI Agents: Transforming Data Analytics Through Agentic AI
AI agents—intelligent software that perceives environments, makes decisions, and takes actions to achieve specific goals—are fundamentally reshaping how people interact with data and systems.

6 Gator-Sized Takeaways from the Gartner Data & Analytics Summit 2025
TLDR: agents on the rise, conversational everything, governance & data quality = king, driving/demonstrating ROI, the power of people never gets old.

Tellius 5.3: Beyond Q&A—Your Most Complex Business Questions Made Easy with AI
Skip the theoretical AI discussions. Get a practical look at what becomes possible when you move beyond basic natural language queries to true data conversations.

Tellius 5.2: Conversational AI for Analytics, Done Right
Tellius 5.2 introduces an adaptive conversational interface with feedback and learnings, enabling two-way dialogue with your cloud-scale data in natural language.

The Pelmorex AI-Driven Analytics Journey
Discover how AI analytics is revolutionizing data-driven decision-making at Pelmorex, a global leader in weather and climate analytics.
.png)
Tellius AI Agents: Driving Real Analysis, Action, + Enterprise Intelligence
Tellius AI Agents transform business intelligence with dedicated AI squads that automate complex analysis workflows without coding. Join our April 17th webinar to discover how these agents can 100x enterprise productivity by turning questions into actionable insights, adapting to your unique business processes, and driving decisions with trustworthy, explainable intelligence.


Snowflake Summit 2023
Tellius is a Green Circle sponsor at Snowflake Summit 2023. Hear how eBay is is taking self-service data exploration to the next level. Stop by Booth 1751 to win some great prizes.