Why Your Revenue Never Adds Up—And How Smart Semantic Stacks Will Fix It
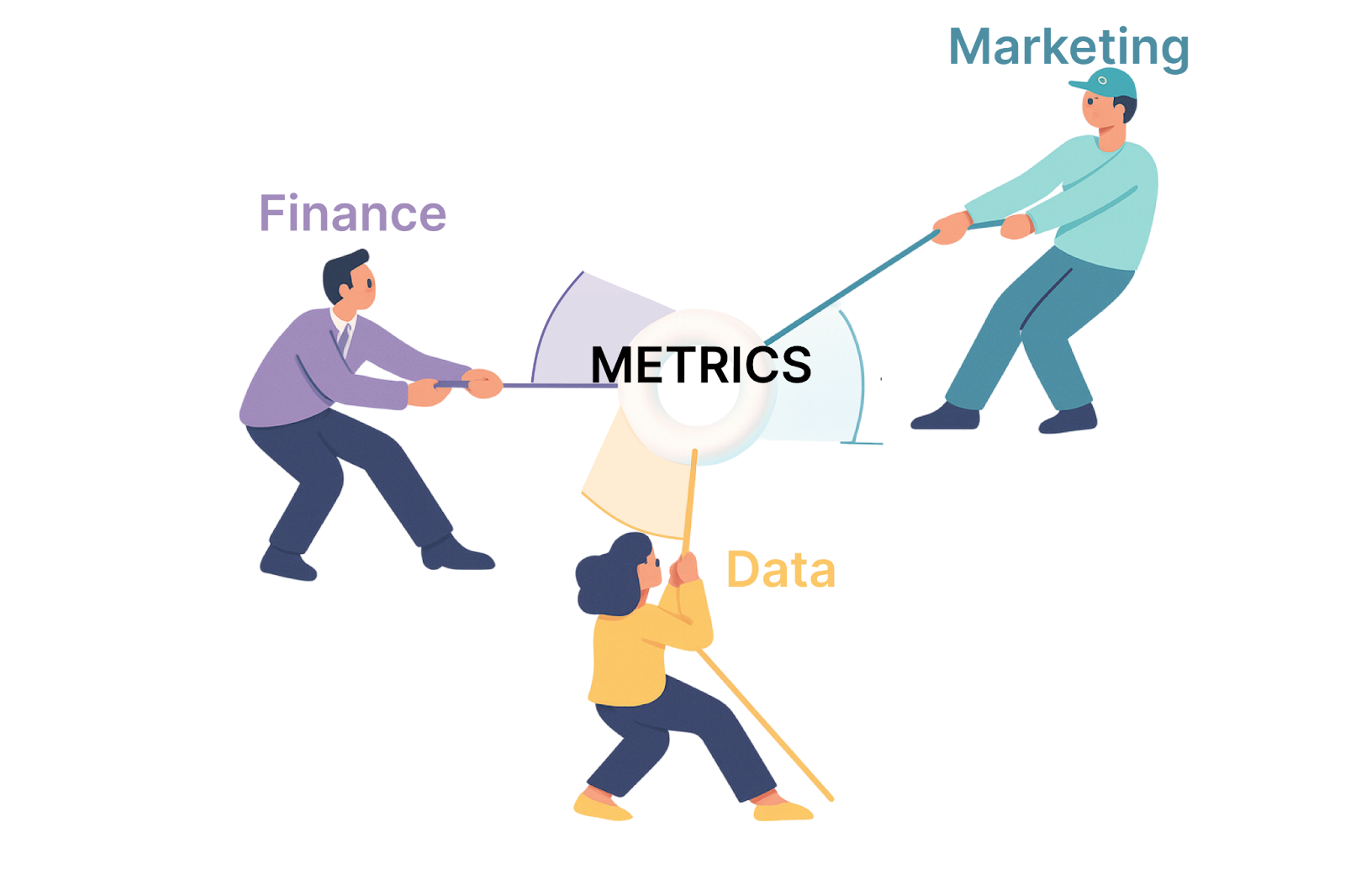

Tell me whether you’ve noticed this: Everyone in tech is talking about semantic layers, but if you talk with the field-level users, you will find endless debates about "metrics layers", complaints about dbt limitations, and heated discussions about why their company's revenue calculations never match between Excel and dashboards.
Here’s the real problem: mismatched revenue definitions aren’t just annoying — they erode trust in data, slow decisions, and cost companies millions. If your CEO asks “What’s our actual revenue?” and three teams give three different answers, you don’t have a technology gap. You have a trust gap. This post is about how a smarter semantic stack can close it — and make AI analytics actually deliver business value.
The metrics layer war nobody talks about
.png)
First, let's address the elephant in the room. The "semantic layer" term is mostly vendor speak. Real practitioners call it the metrics layer, and there's a full-blown war happening between dbt and Google (who owns Looker). Industry observers note that these two "broke the startups, annexed their syntaxes" in what's been called "The Great Metrics War."
The community verdict on dbt metrics? You need time dimensions for everything. You can only do basic aggregation from single tables. If you want to do something slightly complex, too bad.
But here’s the deeper business impact: scattered metrics definitions. Finance calculates revenue one way in Excel. The data team calculates it differently in the warehouse. Marketing has their own version in their BI tool. These calculations drift apart over time, or more often, they never matched in the first place. As Benn Stancil noted, this is "the missing piece of the modern data stack."
And now, with AI entering the picture, the cost of this misalignment is about to spike.
How AI changed everything (and made it worse)
Enter generative AI, and suddenly everyone wants to ask their data questions in plain English. "Show me revenue by region for Q3" sounds simple enough, right?
Wrong. The AI needs to know: What do you mean by revenue? Gross or net? Which currency? What about returns? What defines a region? Is it billing address or shipping address? What if an order spans quarters?
Without clear, shared definitions, AI analytics can’t deliver accurate answers — and inaccurate answers erode trust faster than no answers at all. The semantic stack isn’t a “nice to have” for AI; it’s the only way to make AI analytics reliable enough to drive real business impact.
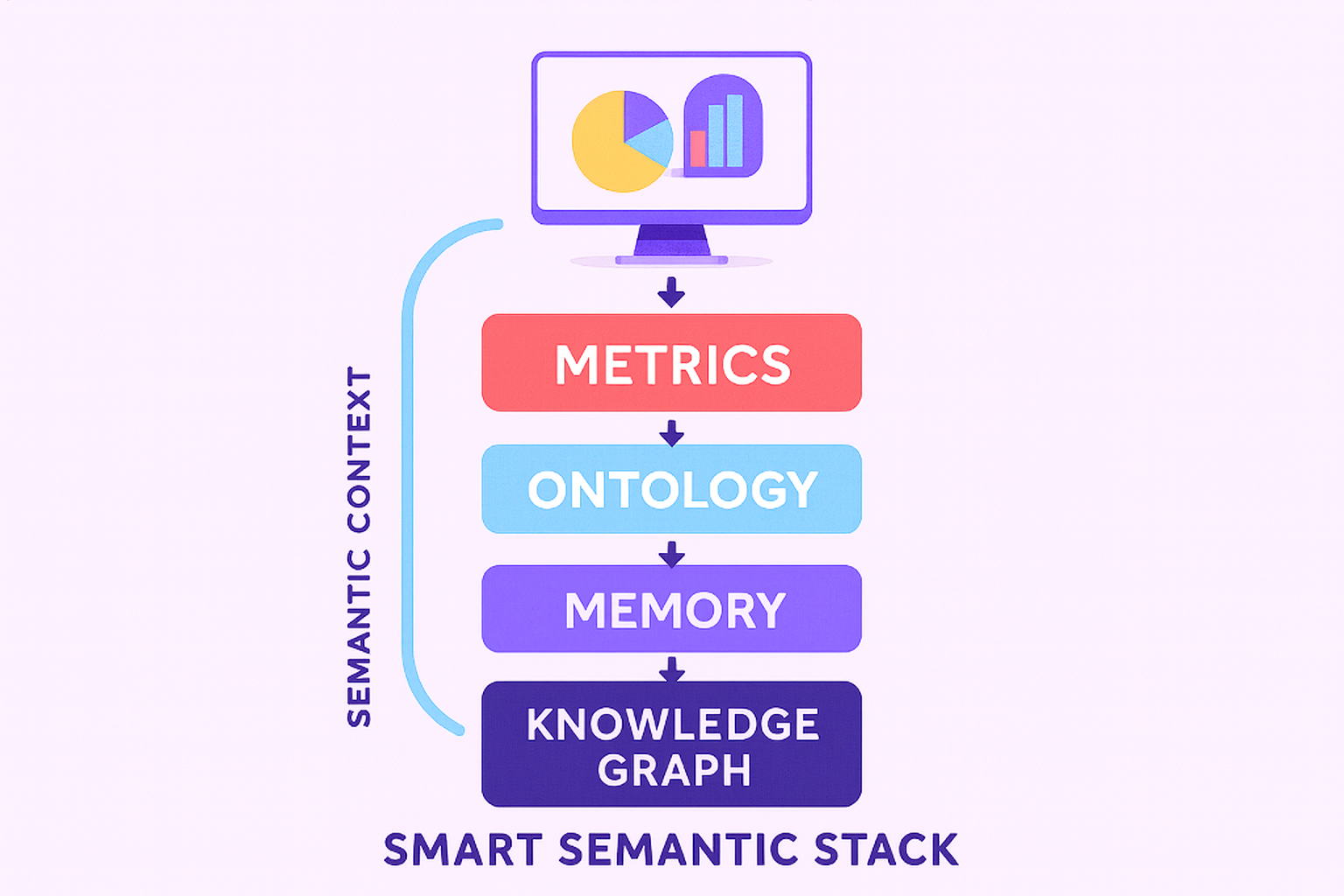
This is where traditional BI falls apart. Those old semantic layers were built for point-and-click dashboards, not for an AI that needs to understand context, remember previous questions, and reason about relationships between data. Modern conversational agent architectures require sophisticated multi-layer approaches.
The new architecture that's emerging looks completely different. Instead of just a metrics layer, you need:
- A metrics layer (the calculations)
- An ontology layer (what things mean and how they relate)
- A memory layer (what the user asked before)
- A context stack (current conversation state)
- A knowledge graph (connecting everything together)
Salesforce figured this out early. Instead of building a custom query processor, they went with SQL generation. Smart move; let the data warehouse do what it's good at while the semantic layer handles the business logic. Their internal tests showed LLM accuracy jumping from 33% to 90% once they added proper semantic context. Cube's research confirms that semantic layers are crucial for natural language querying.
The $30 million reality check
A global bank implemented conversational BI on top of a solid semantic stack and saved $30 million over three years — because every query pulled from one trusted set of definitions. They cut ad-hoc analysis time by 75%. That’s hundreds of analysts no longer wasting hours reconciling numbers.
Enterprise case studies show major retailers slashing their report development time from six months to five weeks. Features that used to take half a year now ship in a month.
But here's the catch: every successful implementation started small. They picked 3-5 critical metrics, got those working perfectly, then expanded. The failures? They tried to semantically model their entire data warehouse on day one. Research shows show that phased approaches deliver faster value and lower risk.
The open source scramble
The open source landscape reveals what developers actually care about. Cube leads with 17.5k GitHub stars because it was built for the cloud era from day one. Developers love it because it just works - good APIs, solid documentation, and you can actually run it in production without selling a kidney.
The dbt Semantic Layer has momentum because, well, everyone uses dbt. But when you talk to the ground-level users, you'll see the pain points: vendor lock-in concerns, pricing anxiety, and those annoying limitations I mentioned earlier.
Then AtScale dropped a bomb by open-sourcing their Semantic Modeling Language (SML). They're betting that standardization will unlock the market. Smart play - if everyone uses the same YAML format for semantic models, switching vendors becomes possible. No more lock-in. "The Boring Semantic Layer" is one of my favorite projects. These folks said forget all the fancy semantic reasoning; just help LLMs write better SQL and stop hallucinating table names. Sometimes boring is exactly what you need.
The dirty secrets nobody mentions
Let's talk about what goes wrong, because that's where the real learning happens.
Performance tanks when you add semantic reasoning. Those beautiful knowledge graphs with billions of relationships become slow. Really slow. Industry-scale implementations like Google's manage 70+ billion assertions across 1 billion entities, but achieving this requires sophisticated distributed architectures. One company I talked to spent six months optimizing queries that took 30 seconds to return. Their users expected sub-second response times.
Governance becomes a nightmare at scale. When you centralize metric definitions, you centralize politics. The finance team wants revenue calculated their way. Sales wants it their way. Marketing has opinions too. Now multiply that by every metric in your company. Semantic layer engineers end up spending more time in meetings negotiating definitions than writing code.
Entity disambiguation in knowledge graphs presents a fascinating cascade of technical challenges that scale exponentially with real-world data complexity.
The Will Smith Problem

When you have 200+ entities named "Will Smith" - actors, athletes, academics, business executives, fictional characters - the system must distinguish between Will Smith (actor, born 1968), Will Smith (NFL player), Will Smith (jazz musician), and dozens of others. Each mention in incoming data could refer to any of these entities, and context alone often proves insufficient. A news article mentioning "Will Smith's latest project" could be a movie, sports tournament, or concert tour.
Multi-Source Confidence Scoring
Enterprise systems typically ingest data from dozens of sources simultaneously - social media APIs, news feeds, internal databases, partner systems, web scraping. Each source has different reliability profiles and contextual strengths. The confidence scoring system keeps it stable:
- Source authority (Reuters vs. random blog)
- Temporal freshness (recent mentions carry more weight for disambiguation)
- Cross-source validation (multiple independent sources mentioning the same entity-context pair)
- Domain expertise (entertainment publications for actor Will Smith, sports sites for athlete Will Smith)
A sophisticated scoring algorithm might assign confidence values like: "85% confident this 'Will Smith' mention refers to the actor based on co-occurring terms 'blockbuster,' 'Hollywood,' and source being Variety."
Provenance Tracking Complexity
Every entity resolution decision needs an audit trail showing exactly how the system reached its conclusion. This means tracking:
- Which specific data sources contributed to the decision
- What contextual clues were weighted most heavily
- When the disambiguation occurred (important for temporal validity)
- Which alternative entities were considered and why they were rejected
- Whether human reviewers validated or overrode algorithmic decisions
Enterprise Implementation Challenges
In production systems, this creates several operational headaches:
- Real-time performance: Disambiguation can't take 30 seconds per entity when processing thousands of mentions per minute
- Consistency across time: The same entity mention should resolve consistently, but the system also needs to adapt as new information emerges
- Human-in-the-loop workflows: When confidence scores are low, routing to human reviewers without creating bottlenecks
- Feedback loops: Learning from corrections to improve future disambiguation accuracy
The metrics layer can actually decrease collaboration. Teams that used to work together start optimizing for their own use cases. They fork definitions. They create team-specific layers. Before you know it, you're back where you started but with more complexity.
What practitioners are actually doing
Forget the hype - here's what works in practice.
- Start with metadata, not data movement. The winning pattern is logical layers that leave data where it lives. Moving data is expensive, slow, and usually unnecessary. Just map the metadata and let your compute layer figure out the rest.
- Use the "push/pull/publish" model for teams. Central team pushes core metrics. Business units pull what they need and add their own. Changes that prove valuable get published back to the center. It's democracy with guardrails.
- Treat your semantic layer like a product, not a project. You need a product manager. You need user feedback. You need iterative releases. The companies that succeed think of their semantic layer as an internal product with internal customers.
- Cache everything, but smartly. Query results, metadata, even parts of your ontology. But build intelligent invalidation - nothing worse than serving stale data because your cache didn't know the underlying data changed. Airbnb's knowledge graph implementation processes millions of entities in real-time using sophisticated caching strategies.
Where this is all headed
2025 is shaping up to be the year semantic layers grow up. Gartner says 75% of analytics will use GenAI for context by 2027. But the real trend is going to be autonomous analytics.
Imagine agents that don't just answer questions but actually make decisions. They'll need semantic layers that can reason, not just calculate. They'll need to understand business rules, compliance requirements, and organizational context.
The tech stack is converging on some clear patterns:
- Your trusty RDBMS for transactional data
- Graph databases for relationships (Neo4j if you're normal, NebulaGraph if you're crazy scale)
- Document stores for all that unstructured mess
- Stream processing to keep everything fresh
- APIs to serve it all up
But over 61% of organizations are already evolving their data and analytics operating models due to AI.
The average GenAI spend hit $1.9 million. Yet less than 30% of CEOs are happy with their ROI. Why? Because they're applying AI band-aids to fundamentally flawed data. The semantic layer is what makes AI actually useful instead of just impressive.
The bottom line
In the evolution from metrics layers to semantic stacks, the winners will be those who get three things right:
- First, they'll start with business value, not technology. Pick the metrics that matter most and nail those before expanding.
- Second, they'll avoid the complexity trap. Every feature you add makes the system harder to govern, slower to query, and more likely to break. Sometimes boring really is better.
- Third, they'll treat this as an organizational change, not a technical one. The hardest part isn't building the semantic layer - it's getting everyone to agree on what "customer" means.
The companies still debating whether to build a semantic layer are asking the wrong question. The question isn't “whether”, it's “how”. And the clock is ticking. Once your competitors can ask their data questions in plain English and get instant, accurate answers, your beautiful dashboards might look outdated.
The future belongs to those who can make data accessible without making it chaotic. That's the real promise of semantic layers, and despite all the challenges, it's a promise worth fighting for. Gartner predicts semantic technologies will take center stage in 2025, powering AI, metadata, and decision intelligence. The window is closing fast.
If your teams can’t agree on what ‘revenue’ means, AI will only accelerate the chaos. Nail your semantic stack now — or watch competitors who do leave you behind.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!


Introducing Tellius AI Agents
Tellius AI Agents and AgentComposer transform business analytics by automating complex multi-step analysis through specialized autonomous agents. Unlike generic chatbots or RPA tools, these agents leverage your enterprise data and business context to deliver deep insights across sales, marketing, finance, and manufacturing—turning questions into actions in minutes instead of days. With no-code agentic workflows, organizations can achieve 100X productivity gains and continuous, data-driven decision making.
%20(2).jpg)
Agentic Analytics Explained: From Questions to Autonomous Action
The next era of analytics is goal-driven, adaptive, and intelligent. Tellius brings this to life by combining deep analytics with conversational intelligence, multi-agent reasoning, and business-aware feedback loops. It’s not about replacing analysts—it’s about scaling intelligence across your business with a system that gets smarter every day.