What it Takes to Build An Enterprise - Grade Agentic Analytics Platform
.png)

If you're leading data and analytics innovation in your organization, chances are you've asked this question recently: Should we build our own GenAI analytics experience—or buy one?
The case for building seems compelling at first glance. Impressive demos flood LinkedIn daily, showcasing AI-powered analytics tools that seem to work like magic. Your data already lives in Snowflake, Databricks, Redshift, or BigQuery. Your team has some LLM expertise. And now you have GenAI-based app development tools that are readily available.
But here's the thing about those smooth demos: they represent the tip of the iceberg. What you don't see is the massive engineering effort required to make conversational analytics work reliably in production, at scale, with real enterprise data.
Let's pull back the curtain and examine what it actually takes to build an enterprise-grade conversational analytics platform.
The Agentic Architecture: More Complex Than It Appears
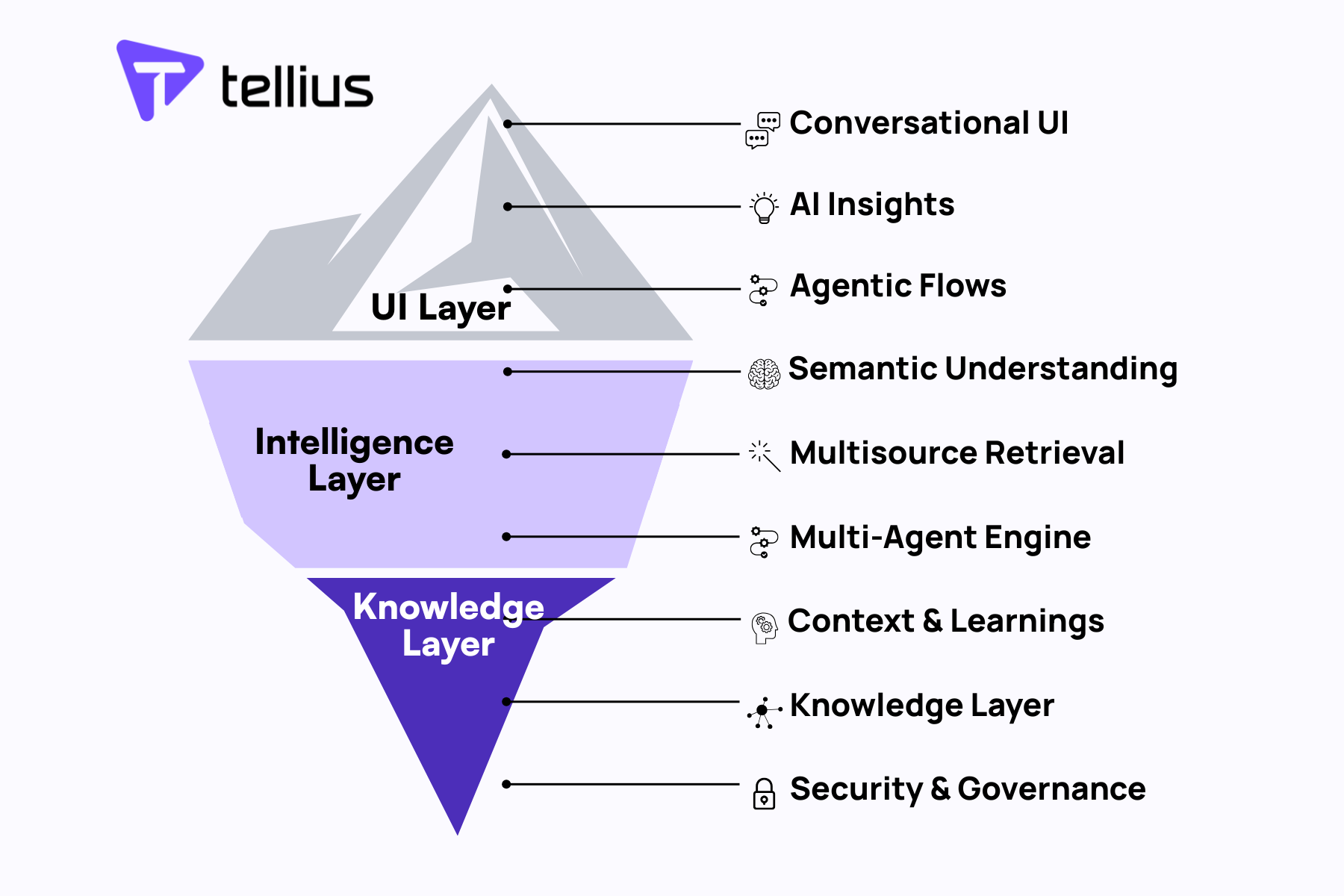
Building conversational analytics isn't just about connecting an LLM to your database. It requires a sophisticated agentic architecture with multiple interconnected components:
The Planner serves as the brain of your system, breaking down complex analytical requests into executable steps. When a user asks "Show me how our Q3 sales performance compares to last year, broken down by region and product category," the planner must understand this requires multiple queries, potentially across different data sources, with proper temporal alignment.
Intent Parsers must handle fundamentally different types of queries, each requiring distinct processing approaches:
- Descriptive queries ("What were our sales last quarter?") need direct data retrieval and aggregation
- Comparative queries ("How do our sales compare to last year?") require temporal alignment and variance calculation
- Diagnostic queries ("Why did sales drop in Q3?") need root cause analysis and correlation detection
- Predictive queries ("What will our revenue be next quarter?") require forecasting models and confidence intervals
- Prescriptive queries ("What should we do to increase retention?") need recommendation engines and scenario modeling
But raw intent classification isn't enough. You need an intermediate Query Planning Layer that translates parsed intent into executable analytical workflows. When a user asks "Show me our best customers," the system must:
- Disambiguate "best" based on user role (sales manager likely means revenue, product manager might mean engagement)
- Determine the appropriate time window and geographical scope
- Identify which customer definition to use (individual vs. account-based)
- Map to available data sources and join requirements
- Generate the analytical execution plan with proper error handling
This query planning layer becomes exponentially more complex with multi-part questions like "Show me our best customers by region and explain why they're performing better than our average customer."
Reflection Mechanisms are crucial for accuracy and require validation at multiple stages. When the system generates an insight like "Sales decreased 15% in the Northeast," it needs to validate this finding, check for data quality issues, and ensure the comparison is meaningful. But most critically, you need a final validation step that verifies whether the generated answer actually addresses the user's original question.
This end-to-end validation is surprisingly complex. If a user asks "Why are we losing customers in the Northeast?" and the system responds with "Sales decreased 15% in the Northeast," the reflection mechanism must recognize that while the data is accurate, it doesn't answer the causal question being asked. The system needs to either redirect to diagnostic analysis or explicitly acknowledge that it's providing descriptive data rather than the explanatory insights requested.
This validation layer must also catch semantic drift—when multi-step analytical processes gradually deviate from the original intent through a series of seemingly reasonable analytical choices.
Tool Calls must orchestrate interactions between your analytics engine, visualization libraries, external APIs, and data sources. Each integration point introduces potential failure modes that need graceful handling.
Core Capabilities: The Engine
Building robust analytics capabilities requires more than running SQL queries:
Deterministic Analytics Processing presents a fundamental challenge: while LLMs excel at understanding user intent and generating explanations, they cannot perform the actual analytical computations. Analytics requires deterministic, mathematically precise results—not probabilistic outputs. Your system needs a robust analytics engine that can execute everything from basic aggregations to complex statistical analyses, while the LLM layer translates user requests into precise analytical operations and interprets results back into natural language. This means building or integrating a framework that can handle seasonality detection, choose appropriate statistical measures, and perform correlation analysis with mathematical accuracy.
Visualization Intelligence goes beyond generating charts. The system needs to choose appropriate visualization types based on data characteristics, handle edge cases like sparse data or extreme outliers, and ensure visualizations remain readable across different screen sizes and accessibility requirements.
But static chart generation is only the beginning. Your system must handle dynamic user interactions like "Change this to a bar chart" or "Show me this as a heatmap instead" while preserving the underlying analytical context. This requires maintaining the relationship between visualization choices and data structure, ensuring that user-requested changes are actually meaningful for the data being displayed.
Even more complex is query refinement handling. When a user asks "Show me sales by region" and then refines to "Actually, show me sales by region for just enterprise customers," the visualization system must seamlessly transition between charts, potentially changing chart types if the data characteristics have fundamentally shifted. The system needs to detect when refinements invalidate previous visualization choices and automatically suggest or implement more appropriate alternatives.
Deep Dive Insights require the system to automatically identify interesting patterns, anomalies, and trends. This means implementing statistical significance testing, change point detection, and correlation analysis—all while explaining findings in business terms.
But users don't just want to know what happened—they want to understand why it happened. This requires a separate Causal Analysis Engine that can perform root cause analysis, attribution modeling, and explanatory analytics. When sales drop 15% in the Northeast, users need the system to automatically investigate potential causes: Was it seasonal? Did a competitor launch? Were there supply chain issues? Did pricing change?
This diagnostic capability requires sophisticated analytical techniques like causal inference, cohort analysis, and multi-variate testing interpretation. The system must understand your business context deeply enough to know which factors are potential causes versus mere correlations. It needs to access external data sources (market conditions, competitor actions, economic indicators) and understand how they might interact with your internal metrics.
Building this explanatory layer is exponentially more complex than descriptive analytics because it requires domain expertise, causal reasoning, and the ability to generate testable hypotheses about business performance.
Forecasting & Predictive Analytics demand sophisticated models that can handle seasonality, trend changes, and external factors. Your system needs to validate model accuracy, handle concept drift, and provide confidence intervals with predictions.
But predictions alone aren't actionable. Users need to understand what happens if they take specific actions. This requires Scenario Analysis and What-If Modeling capabilities that can simulate business outcomes under different conditions. When the system predicts "Revenue will decline 8% next quarter," users immediately ask: "What if we increase marketing spend by 20%?" or "What if we launch that new product feature?"
This scenario modeling engine must understand the complex relationships between controllable variables (pricing, marketing spend, product features) and business outcomes. It needs to account for interaction effects, time delays, and market dynamics. The system must validate that proposed scenarios are realistic and flag when users are testing combinations that fall outside historical patterns or business constraints.
Building this requires econometric modeling, simulation engines, and deep integration with your business planning processes—essentially creating a digital twin of your business operations that can be manipulated to test strategic decisions.
Custom Learning: Adapting to Your Business
Enterprise analytics platforms must learn and adapt to your specific business context.
Domain-Specific Knowledge requires training the system on your business metrics, KPIs, and terminology. "Monthly Active Users" means something different for a SaaS company versus a retail business. But the complexity goes deeper—even different business units within the same company often have conflicting definitions and interpretations.
Marketing might define "customer acquisition cost" differently than Finance. Sales teams might have their own definition of "qualified lead" that doesn't match Marketing's criteria. Product teams might measure "engagement" using different metrics than Customer Success. Your platform needs customizable business glossaries that can be scoped to specific users, teams, or business contexts.
This requires building a sophisticated knowledge management system that can handle overlapping and conflicting definitions while maintaining consistency within each business context. Users need the ability to customize and update these definitions without requiring engineering intervention. The system must also detect when cross-functional queries might be using incompatible definitions and either reconcile them or flag the discrepancy to users.
Managing this semantic complexity across an enterprise organization becomes a significant ongoing operational challenge that requires dedicated governance processes and tooling.
Custom Agents need to be built for different user personas. A CFO asking about profitability needs different insights than a product manager asking about user engagement. But in today's AI-driven environment, users don't just want pre-built agents—they want to author their own autonomous analytics agents that can operate independently within their specific domains.
This requires building a comprehensive Agent Development Platform that allows business users to create specialized agents without coding. Users want agents that can automatically monitor key metrics, detect anomalies, generate insights, and even trigger actions. A sales operations manager might build an agent that monitors pipeline health, automatically investigates conversion rate drops, and suggests corrective actions. A marketing manager might create an agent that continuously analyzes campaign performance and automatically reallocates budget based on performance thresholds.
The platform must provide intuitive tools for defining agent behavior, setting up triggers and conditions, configuring data access permissions, and establishing approval workflows for automated actions. Users need to be able to test, debug, and iterate on their agents without technical support.
This agent authoring capability transforms your platform from a query-response system into an autonomous analytics ecosystem where specialized AI agents work continuously on behalf of different business functions.
Conversational Context must be maintained across sessions. When a user returns to ask "What about last month?" the system needs to remember previous conversations and analysis context.
Handling the Messy Reality of Conversations
Real users don't interact with analytics systems like they do in demos. They make typos, ask ambiguous questions, and change their minds mid-conversation. Your system needs robust conversational rules:
Failure Mode Handling must gracefully manage scenarios where queries can't be answered, data is missing, or analysis fails. Users need clear explanations, not cryptic error messages.
Clarification Protocols should automatically identify when questions are ambiguous and ask for clarification in natural language. "I can show you customer acquisition costs by marketing channel or by time period. Which would be more helpful?"
Retry Logic needs to handle various failure scenarios—from temporary database connectivity issues to LLM API rate limits—without losing user context.
Edge Case Management covers everything from handling empty result sets to managing queries that would return millions of rows.
Data Preparation: The Hidden Complexity
Your analytics platform is only as good as the data it analyzes, and enterprise data is notoriously messy:
Multi-Source Integration requires connecting to various systems, each with different schemas, update frequencies, and reliability characteristics. Your customer data might live in Salesforce, transaction data in your ERP system, and behavioral data in your data warehouse.
Cleaning and Transformation must handle inconsistent formats, missing values, and data quality issues. When sales data shows negative quantities, your system needs to know whether this represents returns, data entry errors, or legitimate business scenarios.
Custom Business Rules require encoding domain-specific logic. "Revenue" might exclude certain transaction types, or "active customers" might have a specific definition that varies by business unit.
Calculated Metrics need to be computed consistently across different queries and time periods. When a user asks for "growth rate," your system must know whether to calculate month-over-month, year-over-year, or compound annual growth.
LLM Tuning and Context Management
Making large language models work reliably for analytics requires significant customization:
Custom Use Case Training involves fine-tuning models on your specific business scenarios, query patterns, and expected outputs. Generic models often struggle with domain-specific terminology and business logic.
Context Engineering becomes critical as conversations grow longer. Your system must maintain relevant context while discarding noise, balancing comprehensive understanding with token limitations.
Memory Management requires both short-term conversation memory and long-term user preference learning. The system should remember that this user typically looks at data by product category, while another prefers regional breakdowns.
Quality Assurance and Testing
Unlike traditional software, AI-powered analytics systems require specialized testing approaches:
Accuracy Validation must continuously verify that generated insights are correct. This requires automated testing against known datasets and ongoing monitoring of result quality.
Bias Detection needs to identify when the system might be producing skewed results due to training data limitations or algorithmic bias.
Regression Testing becomes complex when dealing with probabilistic systems. How do you test that an AI system continues to work correctly when its outputs can vary?
Enterprise-Grade Operations
Production deployment introduces additional complexity layers:
Alerting & Monitoring must track not just system uptime, but also insight quality, user satisfaction, and business impact. When accuracy degrades, you need to know immediately.
User Management requires integration with existing identity systems, role-based access control, and audit trails that meet compliance requirements.
Data Security and Privacy demand encryption at rest and in transit, data masking for sensitive information, and compliance with regulations like GDPR or HIPAA.
Scalability Planning must account for growing user bases, increasing data volumes, and evolving query complexity. Your system needs to handle both the marketing team's daily reports and the CEO's ad-hoc deep dives.
The Real Timeline and Cost Considerations
Building an enterprise-grade conversational analytics platform typically requires:
- 12-24 months of development with a team of 8-15 specialized engineers
- Ongoing maintenance and improvement as data sources evolve and user needs change
- Significant infrastructure costs for compute, storage, and AI model inference
- Compliance and security audits that can add months to deployment timelines
The total cost of ownership extends far beyond initial development, including ongoing model training, infrastructure scaling, and continuous feature development to stay competitive.
Making the Build vs. Buy Decision
When evaluating whether to build or buy, consider these factors:
Build when you have:
- Unique analytical requirements that existing solutions can't meet
- Significant engineering resources to dedicate long-term
- Highly specific data models that require custom handling
- Regulatory requirements that preclude third-party solutions
Buy when you:
- Need to deploy quickly to capture market opportunities
- Want to focus engineering resources on core business differentiators
- Lack specialized AI/ML expertise in-house
- Require proven enterprise-grade security and compliance
The Path Forward
Building an enterprise-grade conversational analytics platform is an enormous undertaking that requires expertise across multiple disciplines: data engineering, machine learning, user experience design, and enterprise software development. The complexity goes far beyond what's visible in those compelling demos.
For most organizations, the question isn't whether conversational analytics will transform how teams work with data—it's whether you have the resources and expertise to build it right, or whether partnering with a specialized vendor will get you there faster and more reliably.
The key is understanding exactly what "enterprise-grade" means for your organization and making an informed decision based on your specific requirements, resources, and timeline. Either way, the investment in conversational analytics will pay dividends in faster insights, better decision-making, and more engaged data users across your organization.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!



AI Agents: Transforming Data Analytics Through Agentic AI
AI agents aren’t just hype—they’re the engine behind the next generation of self-service analytics. This post breaks down how agentic AI enables multi-step, contextual analysis workflows that automate the grunt work of business intelligence. Learn what makes agentic systems different, what to look for in a true AI-native platform, and how Tellius is pioneering this transformation.
Introducing Tellius AI Agents
Tellius AI Agents and AgentComposer transform business analytics by automating complex multi-step analysis through specialized autonomous agents. Unlike generic chatbots or RPA tools, these agents leverage your enterprise data and business context to deliver deep insights across sales, marketing, finance, and manufacturing—turning questions into actions in minutes instead of days. With no-code agentic workflows, organizations can achieve 100X productivity gains and continuous, data-driven decision making.

5 Common Pitfalls to Avoid When Launching a Self-Service Analytics Program
Here are some common pitfalls we've seen for organizations launching a self-serve analytics vision—and how to avoid them to maximize your odds of success.